译注:这篇文章节选自《用Rust编写一个操作系统》系列。它由浅入深的介绍了分页技术(Paging)的历史由来,以及在现代操作系统中的实现。这是我目前读过的把Paging讲的最清楚的一篇文章,因此将它翻译出来,希望更多的读者能够受益。
原文:https://os.phil-opp.com/paging-introduction/
作者:Philipp Oppermann
翻译:喵叔
分页技术是现代操作系统中常用的一种内存管理方案。这篇文章介绍了我们为什么需要内存隔离(memory isolation),内存分段(segmentation)是怎么实现的,虚拟内存(virtual memory)是什么,以及分页技术是怎样解决内存碎片化(fragmentation)的问题。同时,这里还探讨了在x86_64架构上多级页表的层次结构。
该系列博客使用GitHub进行管理和开发,如果你有任何问题或疑问,请给我开一个issue,你也可以在底部留言。这篇文章的完整代码可以在这里找到。
内存保护
操作系统的一个主要职责就是隔离应用程序,比如说,web浏览器不应该能够干扰到文本编辑器。为了实现此目的,操作系统会利用硬件的某些功能来确保一个进程的内存空间不会被另一个进程访问到。当然,不同的硬件和操作系统也会有不同的实现。
举个栗子,某些ARM Cortex-M处理器(多用于嵌入式系统)具有内存保护单元(MPU),它允许你定义少量具有不同访问权限(例如无访问、只读、读写)的内存区域。在每次发生内存访问的时候,MPU都会确保该地址所在的区域具有合法的访问权限,否则将触发异常。同时在发生进程切换的时候,操作系统也会及时的更新相应区域及其访问权限,这样就确保了每个进程只能访问自己的地址空间,从而达到隔离进程的作用。
另一方面,在x86平台上,硬件支持两种不同的内存保护方式:分段(segmentation)和分页(paging)。
分段
分段技术早在1978年就已经出现,起初是为了增加CPU的寻址空间。当时的情况是CPU只使用16位地址,这将可寻址空间限制为64KiB(216)。为了访问到更高的内存,一些段寄存器被引入进来,每个段寄存器都包含一个偏移地址。CPU将这些偏移地址作为基地址,加到应用程序要访问的内存地址上,这样它就可以使用到高达1MiB的内存空间了。
段寄存器有好几种,CPU会根据不同的内存访问请求而选择不同的段寄存器:对于取指令请求,代码段寄存器CS会被使用;堆栈操作(push/pop)会用到堆栈段寄存器SS;其他操作则使用数据段DS或额外的段ES,后来又添加了两个可以自由使用的段寄存器FS和GS。
在分段技术的第一版实现中,段寄存器直接存放了段偏移量,并且没有访问控制的检查。后来,随着保护模式的引入,这种情况发生了改变。当CPU以这种模式运行时,段寄存器中包含了一个局部或全局描述符表中的索引,该表除了包含偏移地址外,还包含段大小和访问权限。通过为每个进程加载单独的描述符表,操作系统就能将进程的内存访问限制到它自己的地址空间内,从而达到隔离进程的作用。
通过在实际访问发生之前修改要访问的目标地址,分段技术实际上已经在使用一种现在广为使用的技术:虚拟内存。
虚拟内存
虚拟内存背后的思想是将内存地址从底层存储设备中抽象出来。即在访问存储设备前,增加一个地址转换的过程。对于上面的分段来说,这里的转换过程就是为内存地址加上一个段偏移量。例如,当一个进程在一个偏移量为0x1111000的段中访问内存地址0x1234000时,它实际访问到的地址是0x2345000。
为了区分这两种地址类型,我们将转换前的地址称为虚拟地址(virtual),转换后的地址称为物理地址(physical)。这两种地址之间的一个重要区别是物理地址是唯一的,并且总是指向同一个内存位置。而虚拟地址则依赖于转换函数,所以两个不同的虚拟地址完全有可能指向相同的物理地址。同样,相同的虚拟地址在不同的转换函数作用下也有可能指向不同的物理地址。
下面我们将同一个程序并行的运行两次,来看看它的内存映射情况:

在这里,相同的程序运行了两次,但是使用了不同的转换函数。第一个进程实例的段偏移量为100,因此它的虚拟地址0-150被转换为物理地址100-250。第二个进程实例的偏移量为300,所以它的虚拟地址0-150被转换为物理地址300-450。这样就允许了两个进程互不干扰地运行相同的代码并且使用相同的虚拟地址。
这个技术的另一个优点是,不管程序内部使用什么样的虚拟地址,它都可以被加载到任意的物理内存点。这样,操作系统就可以在不重新编译程序的前提下,充分利用所有的内存。
内存碎片
在将内存地址区分为虚拟地址和物理地址之后,分段技术作为连接这两者的桥梁就显得尤为重要。但分段技术的一个问题在于它可能导致内存碎片化。比如,如果我们想在上面两个进程的基础上再运行第三个程序:

可以看到,即便有足够多的空闲内存,我们也无法将第三个进程映射到物理内存中。这里的主要问题是,我们需要连续的大块内存,而不是大量不连续的小块内存。
解决这种碎片化问题的一个办法就是,先暂停程序的执行,移动已使用的内存使他们更紧凑一些,然后更新转换函数,最后再恢复执行:

现在我们有了足够的连续空间来运行第三个进程了。
但在碎片整理的过程中,需要移动大量的内存,这会降低性能。而且这种整理需要定期完成,以免内存变得过于分散。这使得程序会被随机的暂停并且失去响应,所以这种方法会使得程序的性能变得不可预测。
综上,内存碎片化是使得大多数系统不再使用分段技术的原因之一。事实上,64位的x86甚至不再支持分段,而是使用另一种分页技术,因为它可以完全避免这些碎片问题。
分页
分页技术的核心思想是将虚拟内存空间和物理内存空间划分成固定大小的小块,虚拟内存空间的块称为页(pages),物理地址空间的块称为帧(frames)。每一个页都可以单独映射到一个帧上,这使得我们可以将一个大块的虚拟内存分散的映射到一些不连续的物理帧上。
如果回顾刚才内存碎片化的示例,我们可以看到使用分页显然更有优势:

在本例中,我们的页大小为50字节,这意味着我们的每个进程空间都被划分成了三页,每页都单独映射到一个帧,因此连续的虚拟内存空间可以被映射到非连续的物理帧上。这就允许我们在没有执行碎片整理的情况下直接运行第三个程序。
隐藏的碎片
与分段相比,分页使用大量容量较小、但大小固定的内存区域,而不是少量容量较大、但大小可变的区域。因为每个帧都有相同的大小,所以不会出现因帧太小而无法使用的情况,因而也“不会”产生内存碎片。
当然这仅仅是“看起来 ”没有碎片产生,实际上还是会有一些隐藏的碎片,我们称之为“内部碎片”。发生内部碎片是因为不是每个内存区域都正巧是页面大小的整数倍。仍拿上面的程序举例,假如该程序的大小为101字节,我们仍然需要3个大小为50字节的页来装载它,这比实际需要的多占了49个字节。为了区分这两种情况,我们把使用分段而引发的碎片称为“外部碎片”。
虽然内部碎片也不是我们想要的,但比起外部碎片来说要好很多。它仍然会浪费一些内存,但好在不需要碎片整理,并且碎片的总量是可预测的(平均每个内存区域有半页碎片)。
页表
可以看到,可能有数以百万的的内存页被映射到了帧,这里的映射信息是需要额外存放的。在分段技术的实现中,每个活跃的内存单元都有一个单独的段寄存器来存放段信息,但这对于分页来说是不可能的,因为分页的数量远远多于寄存器。分页使用一个名为页表(page table) 的结构来存储它的映射信息。
对于上面的示例,它的页表大概长这个样子:

每个进程都有它自己的页表,我们用一个特殊的寄存器来存放指向当前活动页表的指针。在x86上,该寄存器为CR3。在每次运行一个进程之前,操作系统将负责把正确的指针放到该寄存器中。
在每次发生内存访问时,CPU会从寄存器中读取页表指针,并从页表中查找该页面被映射哪个帧上。这个过程由硬件完成,对程序完全透明。为了加快这里的转换过程,许多CPU都有一个特殊的缓存,用来记住上次转换的结果。
根据架构的不同,页表中的每一项还可以在flags字段中存储访问权限等属性。在上面的例子中,r/w表示该页既可读又可写。
多级页表
我们刚才看到的那个简单的页表存在一个问题:在较大的地址空间中它会浪费内存。例如,假设一个进程使用4个虚拟页面0、1_000_000、1_000_050和1_000_100(这里的_表示千位分隔符):

它只需要4个物理帧,但是页表中有超过100万个项目。而且我们还不能省略空项目,因为这样的话在地址转换的过程中,CPU就不能直接跳转到正确的页表项(例如,不能保证第四页就在页表的第四位)。
为了减少内存的浪费,我们可以使用一个二级页表。这里的第二级页表包含的是内存地址区间跟第一级页表的映射信息。
或许用一个例子能解释的更清楚一点。我们假设每个1级页表负责一个大小为10_000的内存区域,那上面的映射关系可以扩展为:

这里,第0页属于第一个10_000字节区域,因此它的映射关系落入到第二级页表的头一项。这一项指向了一个一级页表T1,而T1又表明,第0页被映射到第0个帧。
另外,第1_000_000、1_000_050和1_000_100页都属于第100个10_000字节区域,所以它们使用第二级页表的第100项。这一项指向了另一个一级页表T2,而T2又将这三个页面分别映射到帧100、150和200。值得注意的是,这里一级页表的页地址不包括区域的偏移量,所以这里映射1_000_050页的那一项写的仅仅是50。
我们在第2级表中仍然有100个空位置,但比之前的百万个空位置要少得多。这是因为我们不需要为10_000和1_000_000之间未映射的内存区域创建1级页表。
两级页表的原理可以扩展到三、四或更多级别。然后,页表寄存器CR3就指向最高级别的页表,该表则指向下一个较低级别的表,这个低级别的表再指向另一个更低一级的表,以此类推。最后,1级页面表指向映射的帧。该原理通常被称为多级 或分层 页表。
现在我们已经了解了分页和多级页表的工作方式,接下来我们来看看x86_64架构是如何实现分页的(下面假设CPU工作在64位模式下)。
x86_64下的分页
x86_64架构使用4级页表,页大小为4KiB。这里每级页表都有固定的512项,每项都为8个字节,因此每个页表的大小为512 * 8B = 4KiB —— 正巧放满一页。
一个虚拟地址的结构如下,它包含每级页表的索引:

可以看到,每级页表的索引都是9比特,这是因为每级页表都有2^9 = 512项。这里最低的12位表示的是该地址在一个4KiB大小的页中的偏移量(2^12 bytes = 4KiB)。第48到64位被丢弃,这意味着x86_64实际上只支持48位地址,所以它并不是真正的64位。虽然有计划通过一个5级页表来将地址扩展到第57位,但是目前还没有生产出支持此功能的处理器。
虽说第48到64位被丢弃,但也不能将它们设为任意值。相反,此范围内的所有bit都必须跟第47位的值一样,这一方面是为了保证地址的唯一性,另一方面也是为了以后的扩展,比如5级页表。这被称为符号扩展 ,因为它与二进制补码中的符号扩展非常相似。 如果地址未进行正确的符号扩展,则CPU会抛出异常。
一个地址转换的实例
让我们通过一个例子来了解这整个转换的过程:

CR3寄存器存放的是当前活动的第4级页表的物理地址,即整个4级页表的根表地址。表中的每一项都指向下一个级别表的物理帧,最终,第1级表中的内容则指向被映射的页帧。值得注意的是,页表中的所有地址都是物理的而不是虚拟的,否则CPU也需要转换这些地址(这会导致无休止的递归)。
上面页表的层次结构映射了两个页面(蓝色)。从页表索引我们可以推断出这两个页面的虚拟地址是0x803FE7F000和0x803FE00000。我们来看看当进程读取地址0x803FE7F5CE时会发生什么。首先,我们将该地址转换为二进制,看看它的页表索引和页面偏移量:

使用这些索引,我们就可以遍历页表的层次结构以确定该地址对应的物理帧:
- 首先,我们从
CR3寄存器中读取第4级页表的物理地址。 - 从上面的二进制表示中,我们可以看到该地址的第4级索引是
1,所以我们查看第4级页表的第一项,它告诉我们第3级表存储在地址16KiB。 - 我们从该地址加载第3级表,并查看索引为0的内容,它将我们带向地址为24KiB的第2级页表。
- 第2级索引是
511,因此我们查看该页表的最后一个项以找出第1级页表的地址。 - 同样的,从第1级页表的第
127项我们终于找到该页被映射到了物理帧12KiB,即十六进制的0xc000。 - 最后一步就是将页面偏移量和帧地址加起来,这样我们就得到了该虚拟地址对应的物理地址0xc000 + 0x5ce = 0xc5ce。

第1级页表的权限标志位为r,表示只读。硬件会强制检查这些权限,如果我们尝试对该页面进行写操作,那将会触发异常。高级别页表中的权限会限制低级别页表的权限,因此如果我们将第3级页表中的第511项设为只读,则由它所指向的页面都不可写,即使在第4级页表中有的页面权限标志位为读写。
需要注意的是,尽管本示例中,每级页表仅有一个实例,但实际上,在一个地址空间中,每级页表通常会有多个实例,包含:
- 一个第4级页表
- 512个第3级页表(第4级页表有512项)
- 512 * 512个第2级页表(每个第3级页表都有512项)
- 512 * 512 * 512个第1级页表(每个第2级页表都有512项)
页表结构
x86_64中的页表实际上是一个长度为512的数组。 用Rust的话说:
|
|
如repr属性所示,页表需要跟页面对齐,即在4KiB的边界上对齐。这可以确保一个页表始终填充满整个页面,并允许内部结构的空间优化。
数组中的每一项大小都为8 bytes(64bits),格式为:
| Bit(s) | Name | Meaning |
|---|---|---|
| 0 | present | 该页已经被加载到内存中 |
| 1 | writable | 该页是可写的 |
| 2 | user accessible | 如果未被设置,只有运行在内核模式下的代码可以访问这个页面 |
| 3 | write through caching | 写操作直接反应到内存中 |
| 4 | disable cache | 该页不使用缓存 |
| 5 | accessed | 在使用该页后,CPU会设置此位 |
| 6 | dirty | 在写操作发生后,CPU会设置此位 |
| 7 | huge page/null | 在P1和P4中必须是0,在P3中则创建1GiB页面,在P2中则创建2MiB页面 |
| 8 | global | 在地址空间切换的时候,该页未从缓存中刷新(必须设置CR4寄存器的PGE位) |
| 9-11 | available | 可以由操作系统自由使用 |
| 12-51 | physical address | 该页跟页帧的52位对齐,或者是下一个页表 |
| 52-62 | available | 可以由操作系统自由使用 |
| 63 | no execute | 禁止执行此页上的代码(必须设置EFER寄存器中的NXE位) |
可以看到只有位12-51被用来存储物理帧的地址,其余的位被用作标志或者可以被操作系统自由使用。这是建立在我们总是指向4096 byes整数倍地址的基础上,这个地址可能是另一个页表,也有可能是一个物理帧。这也意味着第0-11位始终为零,而且硬件会在使用该地址之前将他们置为0,因此我们没有必要存储这些位。第52-63位也是如此,因为x86_64架构仅支持52位物理地址(道理跟它仅支持48位虚拟地址类似)。
下面来详细的解释下这些标志位:
present用来区分已映射页面和未映射页面。当内存用满之后,操作系统会临时的将一些页面交换到磁盘上。随后,如果该页面被访问到了,一个叫缺页中断 的异常会被抛出,那么操作系统就知道需要从磁盘中重新加载这个丢失的页面,然后再继续执行应用程序。writable和no execute分别表示,该页的内容是可写的还是包含可执行的指令。- 当对页面进行读或写操作时,CPU会自动设置
accessed和dirty标记。操作系统可以利用这些信息,来决定比如自上次存盘之后,哪些页可以被换出或者哪些页的内容已经被修改过。 write through caching和disable cache用来控制每一页的缓存。user accessible用来标志该页是否可以被用户空间的代码访问,否则只有内核空间的代码才可以访问。这个特性使得在用户空间的程序运行时,内核代码仍然保持住它的映射,从而加快系统调用。然而,Spectre漏洞仍然允许处于用户空间的代码读取这些页面。global标志用来告诉硬件,该页在所有的地址空间中都可用,因此在发生地址空间切换的时候不需要从缓存中删除(请参阅下面有关TLB的部分)。该标志通常与一个未被设置的user accessible一起使用,用来将内核代码映射到所有地址空间。huge page用在第2级或者第3级页表中表示该页中的每一项都直接指向一个物理帧。有了这个标志后,页面大小将增加512倍,对于第2级的页表项,页面大小变为2MiB = 512 * 4KiB,对于第3级的页表项,页面大小变为1GiB = 512 * 2MiB。使用较大页面的优点是,我们只需要更少的转换缓存行和更少的页表。
Rust里的x86_64包已经有了页表及页表项这两种类型,因此我们不需要自己创建它们。
页表缓存
上面所说的4级页表使得虚拟地址的转换变得很昂贵,因为每次转换都需要4次内存访问。为了提高性能,x86_64架构将最近的几次转换缓存在TLB(translation lookaside buffer)中,这样地址转换就有可能直接从缓存中读取结果。
与其他CPU缓存不同,TLB不是完全透明的,当页表的内容发生变化时,它不会更新或删除缓存,这意味着内核必须在修改页表时手动更新TLB。为此,有一个名为invlpg(invalidate page)的特殊CPU指令,用于从TLB中删除指定页面的转换缓存,以便在下一次访问时从页表中再次加载该页面。另外,还可以通过重新加载CR3寄存器(即模拟一次地址空间切换)来刷新TLB。x86_64包在tlb模块中将这两种方法封装成了不同的Rust函数。
切记,在每次页表修改时都要刷新TLB,否则CPU可能会继续使用旧的转换缓存,这会导致非常难以调试且又不确定的错误。
实现
有一件事还没有提到:我们的内核已经运行在分页上了。我们在“A minimal Rust Kernel”那篇文章中添加的引导程序已经设置了一个4级分页的层次结构,它将内核的每个页面都映射到一个物理帧。这样做主要是因为在x86_64的64位模式下分页是必需的。
这意味着我们在内核中使用的每个内存地址都是一个虚拟地址。访问地址为0xb8000的VGA缓冲区会起作用,是因为引导程序对该页进行了恒等映射 ,即虚拟页0xb8000被映射到物理帧0xb8000。
分页使我们的内核已经相对安全,因为每个超出边界的内存访问都会导致页错误,因此不会有随机的物理内存写入发生。引导程序甚至为每个页都设置了正确的访问权限,这意味着只有包含代码的页是可执行的,以及只有数据页是可写入的。
缺页中断
让我们试着通过访问内核之外的一段内存来引起缺页中断。首先,我们创建一个缺页中断处理程序并将其注册到IDT中,这样我们就可以将出错信息打印出来,而不是看到一个笼统的double fault:
|
|
在发生缺页中断时,CPU会将引起该错误的虚拟地址放置到CR2寄存器中。我们使用x86_64包的Cr2::read函数来读取并打印它。通常,PageFaultErrorCode会提供该错误的更多信息,但目前LLVM存在一个传递无效错误代码的bug,因此我们暂时忽略它。如果缺页中断不被解决,我们的代码就无法继续执行,因此最后我们进入了一个hlt_loop的循环。
现在,让我们来访问内核之外的一段内存:
|
|
运行之后,可以看到我们的缺页中断处理程序被调用了:
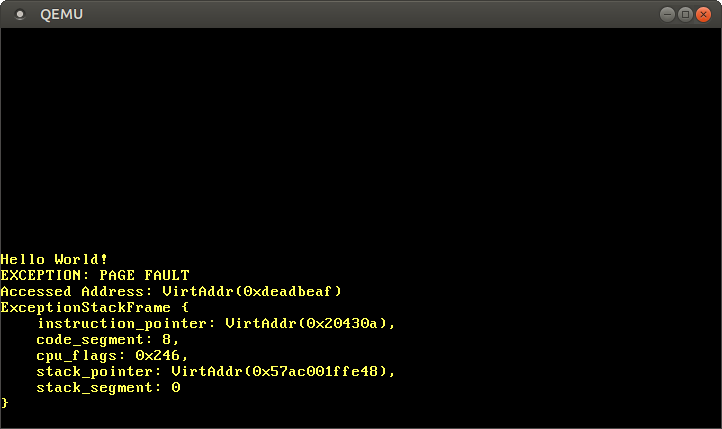
而且CR2寄存器确实包含我们试图访问的地址:0xdeadbeaf。
我们也可以看到当前的指令指针是0x20430a,所以我们知道这个地址指向一个代码页。代码页由引导加载程序以只读的方式映射,因此该地址允许读操作,而不允许写操作。让我们把0xdeadbeaf指针改为0x20430a来测试一下:
|
|
如果注释掉最后一行,我们看到读操作有效,但写操作会导致页错误。
访问页表
让我们看看内核运行时的页表:
|
|
我们使用x86_64包的Cr3::read函数从CR3寄存器中读取当前活动的第4级页表,这个函数的返回值是一个二元组:PhysFrame和Cr3Flags,我们只关心页帧(frame),所以暂时忽略第二个返回值。
运行之后,可以看到这样的输出:
|
|
可以看到,输出的是一个PhysAddr类型,它包装的是当前活动的第4级页表的物理地址0x1000,现在的问题就变成:我们如何从内核中访问该页表?
当分页处于激活状态时,我们不可能直接访问物理内存,否则一个程序就可以很轻易地绕过内存保护来访问另一个程序的内存。因此,访问该表的唯一方法就是通过一个被映射到物理地址0x1000的虚拟页。而为页表的物理帧创建映射是一个常见的问题,比如当内核在为新线程分配堆栈时,它就需要访问页表。
下一篇文章将详细介绍此问题的解决方案。现在,我们只需要知道引导程序使用一种叫递归页表 的技术将虚拟地址空间的最后一页映射到第4级页表的物理帧。虚拟地址空间的最后一页是0xffff_ffff_ffff_f000,所以我们可以通过它来读取该表的内容:
|
|
首先,我们将这个地址强制转换为一个u64类型的指针,因为正如上一节所提到的,每个页表项都是8个字节(64位),因此u64正巧可以装下一项。然后再使用for循环打印页表的前10项,在循环内部,我们使用unsafe块来读取原始指针,使用offset方法来执行指针的偏移运算。
运行之后,是这样的结果:
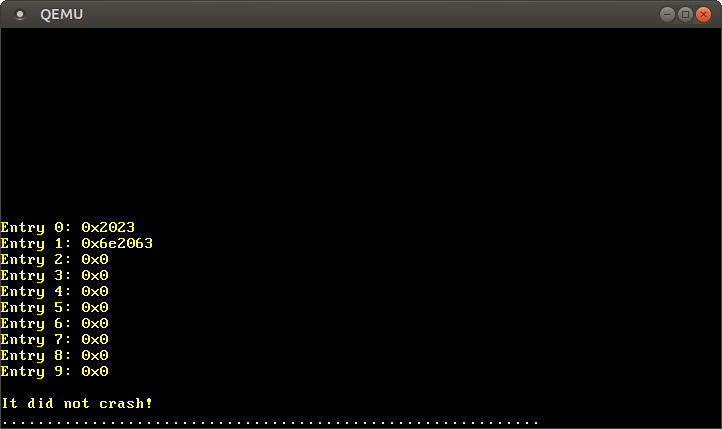
同样,由页表结构那一节可知,第0项的0x2023表示该项存在、可写、已被CPU访问过,并且映射到帧0x2000。第1项也有相同的标志位,并且被映射到0x6e2000,除此之外,它还有一个表示该页已被写入的dirty标志。第2-9项全为0,表示它们还未被加载到内存中,因此这些范围内的虚拟地址还没有被映射到任何物理地址上。
当然,如果不想使用不安全的原始指针,我们也可以使用x86_64包所提供的PageTable类型:
|
|
我们先将0xffff_ffff_ffff_f000转换为一个原始指针,然后再把它变为一个Rust的引用,这个操作仍然需要在unsafe块中进行,因为编译器并不知道能不能访问该地址。在转换完成之后,我们就有了一个安全的&PageTable类型,它能让我们使用数组索引的方式来访问各个页表项。
该类型还为每个页表项的属性提供了描述信息,因此在打印的时候我们就可以直观的看到,哪些标志位被设置了:
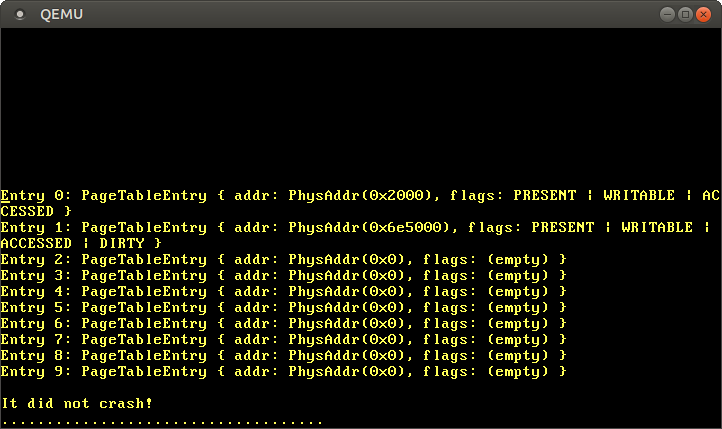
下一步就是顺着第0或者1个页表项的指针追踪到第3级页表。但同样的问题,这里的0x2000和0x6e5000都是物理地址,我们不能直接访问它们。这个问题将在下一篇文章中解决。
总结
本文介绍了两种内存保护技术:分段和分页。前者使用的是可变大小的内存区域,但会引发外部碎片;后者使用的是固定大小的页面,并支持更细粒度的访问权限控制。
分页技术将页的映射信息存在页表当中,页表之间可以组织出支持多个级别的层次结构。x86_64架构使用的是4级页表和4KiB页大小。硬件会自动遍历页表,并在TLB中缓存转换结果。该缓存区不会自动更新,因此需要在每次页表有变化的时候手动刷新。
我们了解到内核已经运行在分页技术上,并且非法的内存访问会导致页错误。我们还尝试访问当前活动的页表,但只能访问到第4级页表,因为页表中存储的是物理地址,而我们不能从内核中直接访问物理地址。
下一步?
下一篇文章将在这篇文章的基础上更深入一步,介绍一种叫递归页表 的技术,用来解决我们刚才遇到的内核代码不能直接访问页表的问题。这个技术允许我们遍历整个页表的层次结构,并且用软件实现地址转换功能。同时,我们还将介绍怎样在已有的页表中添加一个新的映射关系。