在 Go 语言标准库中,sync/atomic包将底层硬件提供的原子操作封装成了 Go 的函数。但这些操作只支持几种基本数据类型,因此为了扩大原子操作的适用范围,Go 语言在 1.4 版本的时候向sync/atomic包中添加了一个新的类型Value。此类型的值相当于一个容器,可以被用来“原子地"存储(Store)和加载(Load)任意类型的值。
历史起源
我在golang-dev邮件列表中翻到了14年的这段讨论,有用户报告了encoding/gob包在多核机器上(80-core)上的性能问题,认为encoding/gob之所以不能完全利用到多核的特性是因为它里面使用了大量的互斥锁(mutex),如果把这些互斥锁换成用atomic.LoadPointer/StorePointer来做并发控制,那性能将能提升20倍。
针对这个问题,有人提议在已有的atomic包的基础上封装出一个atomic.Value类型,这样用户就可以在不依赖 Go 内部类型unsafe.Pointer的情况下使用到atomic提供的原子操作。所以我们现在看到的atomic包中除了atomic.Value外,其余都是早期由汇编写成的,并且atomic.Value类型的底层实现也是建立在已有的atomic包的基础上。
那为什么在上面的场景中,atomic会比mutex性能好很多呢?作者 Dmitry Vyukov 总结了这两者的一个区别:
Mutexes do no scale. Atomic loads do.
Mutex由操作系统实现,而atomic包中的原子操作则由底层硬件直接提供支持。在 CPU 实现的指令集里,有一些指令被封装进了atomic包,这些指令在执行的过程中是不允许中断(interrupt)的,因此原子操作可以在lock-free的情况下保证并发安全,并且它的性能也能做到随 CPU 个数的增多而线性扩展。
好了,说了这么多的原子操作,我们先来看看什么样的操作能被叫做原子操作 。
原子性
一个或者多个操作在 CPU 执行的过程中不被中断的特性,称为原子性(atomicity) 。这些操作对外表现成一个不可分割的整体,他们要么都执行,要么都不执行,外界不会看到他们只执行到一半的状态。而在现实世界中,CPU 不可能不中断的执行一系列操作,但如果我们在执行多个操作时,能让他们的中间状态对外不可见,那我们就可以宣称他们拥有了"不可分割”的原子性。
有些同学可能不知道,在 Go(甚至是大部分语言)中,一条普通的赋值语句其实不是一个原子操作。例如,在32位机器上写int64类型的变量就会有中间状态,因为它会被拆成两次写操作(MOV)——写低 32 位和写高 32 位,如下图所示:

如果一个线程刚写完低32位,还没来得及写高32位时,另一个线程读取了这个变量,那它得到的就是一个毫无逻辑的中间变量,这很有可能使我们的程序出现诡异的 Bug。
这还只是一个基础类型,如果我们对一个大小超过 Cache Line 的结构体进行赋值,那它出现并发问题的概率就更高了。很可能写线程刚写完一小半的字段,读线程就来读取这个变量,那么就只能读到仅修改了一部分的值。这显然破坏了变量的完整性,读出来的值也是完全错误的。
面对这种多线程下变量的读写问题,我们的主角——atomic.Value登场了,它使得我们可以不依赖于不保证兼容性的unsafe.Pointer类型,同时又能将任意数据类型的读写操作封装成原子性操作(让中间状态对外不可见)。
使用姿势
atomic.Value类型对外暴露的方法就两个:
v.Store(c)- 写操作,将原始的变量c存放到一个atomic.Value类型的v里。c = v.Load()- 读操作,从线程安全的v中读取上一步存放的内容。
简洁的接口使得它的使用也很简单,只需将需要作并发保护的变量读取和赋值操作用Load()和Store()代替就行了。
下面是一个常见的使用场景:应用程序定期的从外界获取最新的配置信息,然后更改自己内存中维护的配置变量。工作线程根据最新的配置来处理请求。
|
|
内部实现
罗永浩浩曾说过:
Simplicity is the hidden complexity
我们来看看在简单的外表下,它到底有哪些 hidden complexity。
数据结构
atomic.Value被设计用来存储任意类型的数据,所以它内部的字段是一个interface{}类型,非常的简单粗暴。
|
|
除了Value外,这个文件里还定义了一个ifaceWords类型,这其实是一个空interface (interface{})的内部表示格式(参见runtime/runtime2.go中eface的定义)。它的作用是将interface{}类型分解,得到其中的两个字段。
|
|
写入(Store)操作
在介绍写入之前,我们先来看一下 Go 语言内部的unsafe.Pointer类型。
unsafe.Pointer
出于安全考虑,Go 语言并不支持直接操作内存,但它的标准库中又提供一种不安全(不保证向后兼容性) 的指针类型unsafe.Pointer,让程序可以灵活的操作内存。
unsafe.Pointer的特别之处在于,它可以绕过 Go 语言类型系统的检查,与任意的指针类型互相转换。也就是说,如果两种类型具有相同的内存结构(layout),我们可以将unsafe.Pointer当做桥梁,让这两种类型的指针相互转换,从而实现同一份内存拥有两种不同的解读方式。
比如说,[]byte和string其实内部的存储结构都是一样的,但 Go 语言的类型系统禁止他俩互换。如果借助unsafe.Pointer,我们就可以实现在零拷贝的情况下,将[]byte数组直接转换成string类型。
|
|
知道了unsafe.Pointer的作用,我们可以直接来看代码了:
|
|
大概的逻辑:
- 第5~6行 - 通过
unsafe.Pointer将现有的和要写入的值分别转成ifaceWords类型,这样我们下一步就可以得到这两个interface{}的原始类型(typ)和真正的值(data)。 - 从第7行开始就是一个无限 for 循环。配合
CompareAndSwap食用,可以达到乐观锁的功效。 - 第8行,我们可以通过
LoadPointer这个原子操作拿到当前Value中存储的类型。下面根据这个类型的不同,分3种情况处理。
- 第一次写入(第9~24行) - 一个
Value实例被初始化后,它的typ字段会被设置为指针的零值 nil,所以第9行先判断如果typ是 nil 那就证明这个Value还未被写入过数据。那之后就是一段初始写入的操作:runtime_procPin()这是runtime中的一段函数,具体的功能我不是特别清楚,也没有找到相关的文档。这里猜测一下,一方面它禁止了调度器对当前 goroutine 的抢占(preemption),使得它在执行当前逻辑的时候不被打断,以便可以尽快地完成工作,因为别人一直在等待它。另一方面,在禁止抢占期间,GC 线程也无法被启用,这样可以防止 GC 线程看到一个莫名其妙的指向^uintptr(0)的类型(这是赋值过程中的中间状态)。- 使用
CAS操作,先尝试将typ设置为^uintptr(0)这个中间状态。如果失败,则证明已经有别的线程抢先完成了赋值操作,那它就解除抢占锁,然后重新回到 for 循环第一步。 - 如果设置成功,那证明当前线程抢到了这个"乐观锁",它可以安全的把
v设为传入的新值了(19~23行)。注意,这里是先写data字段,然后再写typ字段。因为我们是以typ字段的值作为写入完成与否的判断依据的。
- 第一次写入还未完成(第25~30行)- 如果看到
typ字段还是^uintptr(0)这个中间类型,证明刚刚的第一次写入还没有完成,所以它会继续循环,“忙等"到第一次写入完成。 - 第一次写入已完成(第31行及之后) - 首先检查上一次写入的类型与这一次要写入的类型是否一致,如果不一致则抛出异常。反之,则直接把这一次要写入的值写入到
data字段。
这个逻辑的主要思想就是,为了完成多个字段的原子性写入,我们可以抓住其中的一个字段,以它的状态来标志整个原子写入的状态。这个想法我在 TiDB 的事务实现中看到过类似的,他们那边叫Percolator模型,主要思想也是先选出一个primaryRow,然后所有的操作也是以primaryRow的成功与否作为标志。嗯,果然是太阳底下没有新东西。
如果没有耐心看代码,没关系,这儿还有个简化版的流程图:
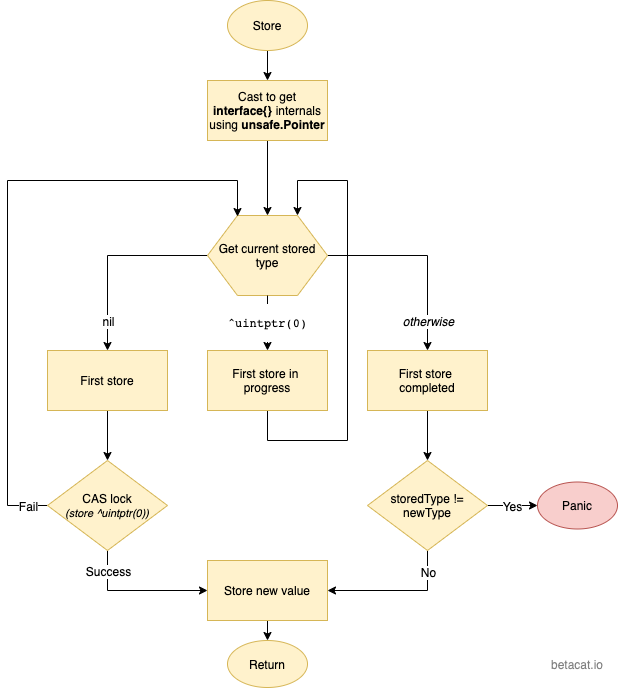
读取(Load)操作
先上代码:
|
|
读取相对就简单很多了,它有两个分支:
- 如果当前的
typ是 nil 或者^uintptr(0),那就证明第一次写入还没有开始,或者还没完成,那就直接返回 nil (不对外暴露中间状态)。 - 否则,根据当前看到的
typ和data构造出一个新的interface{}返回出去。
总结
本文从邮件列表中的一段讨论开始,介绍了atomic.Value的被提出来的历史缘由。然后由浅入深的介绍了它的使用姿势,以及内部实现。让大家不仅知其然,还能知其所以然。
另外,再强调一遍,原子操作由底层硬件支持,而锁则由操作系统的调度器实现。锁应当用来保护一段逻辑,对于一个变量更新的保护,原子操作通常会更有效率,并且更能利用计算机多核的优势,如果要更新的是一个复合对象,则应当使用atomic.Value封装好的实现。