众所周知 (?),字节跳动内部主要使用 Thrift 作为 RPC 的序列化及传输协议。据说这套技术栈是从 99 房继承过来的,那个时候创业公司也没几个 RPC 框架可选,国内小公司基本用的都是 Thrift。
正常流程下,研发一般先写一个语言无关的 thrift 文件,然后由工具生成 Server 端和对应的 Client 端的代码。但某一天,突然“插进来”一个紧急需求(有哪个需求不是紧急插入的?)——要从生成的 Go 代码中,反推出原始的 thrift。作为工具人的我们,拒需求的能力没有,但自嗨的工具倒是不少,这次打算使用的工具就是抽象语法树 AST。
构建 AST
了解过编译原理的同学可能知道,编译器的前端工作大致可以分成三步:

所以为了构建一个 AST,我们需要前序的词法和语法分析,不过幸好 Go 语言的标准库中自带一个实现,我们不需要重复实现一个语言标准的解析器了。拿上面的步骤举例,它们分别对应的实现位于:
- Token——go/token
- 词法分析——go/scanner
- 语法解析——go/parser
- 语法树——go/ast
先把基础打牢,我们挨个介绍一下:
go/token
go/token包用来表示源代码被分割成的一个个token。它主要提供了两种属性—— 类型和位置信息。
类型由包中定义的常量表示,比如一个变量申明语句var sum int = 3 + 2解析出来的 token 就会带上这样的类型属性:
1
2
3
4
5
6
7
8
9
|
var sum int = 3 + 2
| | | | | | |
| | | | | | token.INT
| | | | | token.ADD
| | | | token.INT
| | | token.ASSIGN
| | token.IDENT
| token.IDENT
token.VAR
|
而位置信息则由Position表示,它包含的信息有该 token 所在的文件、行号和列号。比如我们常见的编译错误前面的位置信息就由它提供。
1
|
main.go:14:2: undefined: abc
|
如果一次编译中涉及到多个源文件,那我们就需要用FileSet来记录多个文件中的 token 位置信息。
接下来再看看怎样拿到这些 token 信息。
go/scanner
Scanner有时也被称作Lexer,它的输入是代表源代码的[]byte数组,输出是一个个的token(包括位置信息)。用法是不断的调用Scan方法,直到遇到 token.EOF:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
src := []byte(`var sum int = 3 + 2`)
// 初始化一个 scanner
var s scanner.Scanner
fset := token.NewFileSet()
file := fset.AddFile("demo", fset.Base(), len(src)) // 这里使用一个假文件
s.Init(file, src, nil, scanner.ScanComments) // 需要识别出注释
// 启动 scanner
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
}
|
有了 token 之后,我们就需要来理解这些 token 了,比如怎么知道上面是一条变量申明语句?这时就需要构建出 AST了。
go/parser
go/parser是个集大成者,它的输出是个 AST,但输入却不需要是之前的 token 流,而可以是最原始的源代码,即它帮我们完成了循环调用Scanner生成Token那一堆模板代码。内部实现中,它根据 Scan 出来的不同 Token,构建出不同的 AST 节点,最终连接成一棵语法树。
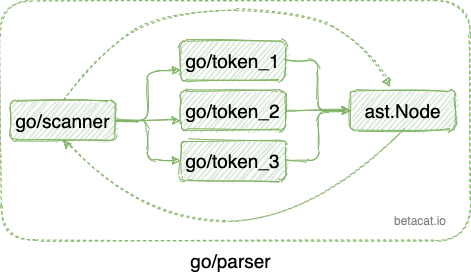
在它的封装下,我们从源代码构建出 AST 就是一个函数调用的事情,底层的 Scanner 和 Token 都被屏蔽掉了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
src := []byte(`
package main
func ssa() int {
var sum int = 3 + 2
return sum
}`)
fset := token.NewFileSet()
// 这里的参数基本是原封不动的传给了scanner的Init函数
node, err := parser.ParseFile(fset, "demo", src, parser.ParseComments)
if err != nil {
panic(err)
}
// 以层次结构输出语法树
ast.Fprint(os.Stdout, fset, node, nil)
}
|
go/ast
上一步会输出非常详细的 AST,结果也很长,限于篇幅我就不贴了,感兴趣的同学可以自行运行一下看看完整的 AST 结构,也可以通过在线的GoAst Viewer查看。这里只画一张函数ssa的简图:
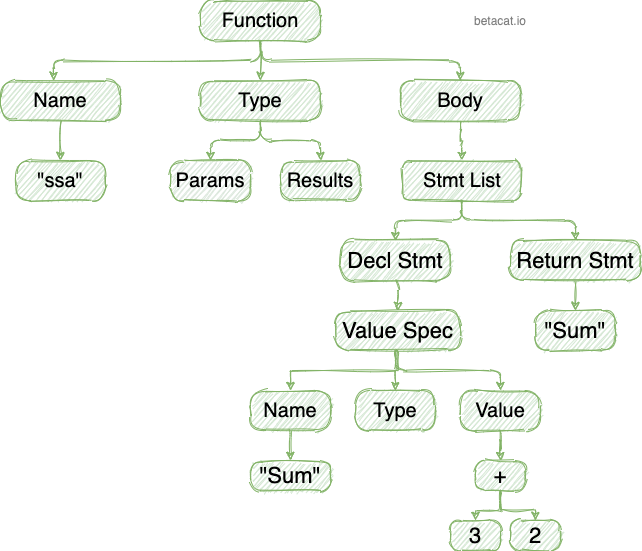
这个结构就是在 go/ast中定义的。跟go/token包一样,它里面也定义了很多类型,用来表示语法树中的不同节点。所有的节点都实现了Node类型。
我们以刚刚最后的加法语句3 + 2为例,它在 AST 中的节点就是一个BinaryExpr:
1
2
3
4
5
6
|
type BinaryExpr struct {
X Expr // left operand
OpPos token.Pos // position of Op
Op token.Token // operator
Y Expr // right operand
}
|
其中的Op就是加号+,X 为3,Y为2。
同样的再往上一层,var sum int = 3 + 2需要一个ValueSpec类型来表示:
1
2
3
4
5
6
7
|
type ValueSpec struct {
Doc *CommentGroup // associated documentation; or nil
Names []*Ident // value names (len(Names) > 0)
Type Expr // value type; or nil
Values []Expr // initial values; or nil
Comment *CommentGroup // line comments; or nil
}
|
它的Names数组只有一项,是变量名sum;Type则是int;而Values数组也只有一项,就是刚刚分析过的BinaryExpr。
这样一层一层的叠加起来,我们就得到了一棵语法树 AST。
遍历 AST
一棵 AST 信息量非常大,我们可能只对其中某些节点感兴趣,这时候就需要对它的节点进行遍历了。根据go/ast中定义的类型信息,我们很容易写出这样的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
node, err := parser.ParseFile(fset, "demo", src, parser.ParseComments)
// 遍历所有的申明
for _, decl := range node.Decls {
// 寻找其中的函数申明
fn, ok := decl.(*ast.FuncDecl)
if !ok {
continue
}
for _, stmt := range fn.Body.List {
// 寻找函数体中的变量申明
declStamt, ok := stmt.(*ast.DeclStmt)
if !ok {
continue
}
// 对变量申明递归下去,可以找到其中的ValueSpce, BinaryExpr等...
}
}
|
由于这是一个很常见的场景,用的代码几乎也是千篇一律的,所以标准库也进行了抽象——它允许业务代码以访问者(Visitor)的模式注入进来,这样,在对整颗树进行了深度优先遍历的时候,就能让访问者有机会处理到 AST 中的每一个节点。
1
2
3
4
5
6
7
8
9
|
node, err := parser.ParseFile(fset, "demo", src, parser.ParseComments)
// 遍历并回调业务代码
ast.Inspect(node, func(n ast.Node) bool {
binaryExpr, ok := n.(*ast.BinaryExpr)
if !ok {
return true
}
// 直接拿到深层的BinaryExpr,并进行处理...
})
|
代码是不是瞬间简单明了了很多?!
反推 thrift
基础终于介绍完了,可以看到,Go 标准库中的这一套组合拳打的还算中规中矩,用法跟其它语言中的 AST 库差异并不大(比如 JS 中的esprima)。总结一下,大家的套路一般都是:
- 先把代码解析成 AST,这应该有现成的库可以使用。
- AST 作为一个树状结构,对它进行深度优先遍历,对遇到的每一个节点,调用业务代码进行处理。
上面的两步属于编译器的前端工作,已经由标准库完成了,接下来的工作就属于编译器后端的范畴了:
- 转换——可以直接对生成的 AST 进行更改,也可以生成一个全新的 AST/model。
- 代码生成——根据上一步生成的 AST/model,再反向输出成代码格式。
这两步一般需要根据业务的需求做一些定制开发。在反推 thrift 的场景中,我们选择第二种,构建出自己的 model,然后在代码生成阶段输出成 thrift 文件。
转换 AST
在 AST 的 Visitor 中,我们有机会检查到每一个节点,这时可以根据一些特征,识别出有明显 thrift 痕迹的节点即可。
举个栗子🌰,thrift 中struct的定义大概长这个样子:
1
2
3
4
|
struct Demo {
1: i32 id,
2: optional string comment,
}
|
由它生成的代码大概是这样子的:
1
2
3
4
|
type Demo struct {
Id int32 `thrift:"id,1" json:"id"`
Comment *string `thrift:"comment,2" json:"comment,omitempty"`
}
|
这里的特征就很明显了,Demo类型中的字段都有thrift这个 tag,且该 tag 的第一个参数表示它在源 thrift 文件中的名字,第二个参数表示该字段的 id。字段Comment是*string指针类型,表明它在 thrift 中有optional修饰符。
根据这些条件,我们可以写出相应的解析规则,这里提供一份伪代码供参考。
首先定义一下期望转换后的 model:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// ThriftStruct is similar to go struct, except its field name comes from the thrift tag
type ThriftStruct struct {
Name string
Fields []ThriftStructField
}
// ThriftStructField represents a field in thrift struct, eg. Id int32 `thrift:"id,1" json:"id"`
type ThriftStructField struct {
ID string
Name string
Type string
Required string
IsArray bool
}
|
在遍历 AST 的过程中插入检查代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
ast.Inspect(file, func(n ast.Node) bool {
switch node := n.(type) {
case *ast.TypeSpec:
if !node.Name.IsExported() {
return false
}
switch structType := node.Type.(type) {
case *ast.StructType: // 如果是struct定义,就检查它是不是有thrift生成的痕迹
sd := ThriftStruct{ // 初始化自己的model
Name: node.Name.Name,
}
for _, f := range structType.Fields.List {
for range f.Names {
tags, _ := structtag.Parse(strings.Trim(f.Tag.Value, "`"))
thriftTag, _ := tags.Get("thrift") // 检查 field tag。限于篇幅其他的检查已被省略
if len(thriftTag.Options) == 0 {
return false
}
required := true // 检查是不是可选的
if _, ok := f.Type.(*ast.StarExpr); ok {
required = false
}
sd.Fields = append(sd.Fields, ThriftStructField{
ID: thriftTag.Options[0],
Name: thriftTag.Name,
Type: PrintExpr(f.Type),
Required: required,
})
}
}
}
return false
}
return true
})
|
好了,一个 thrift struct类型就解析好了,我们拿到了自己的ThriftStruct类型。
代码生成
代码生成可以理解为对自定义 model 的一种序列化操作,还拿刚才的🌰:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (ts *ThriftStruct) String() string {
fields := make([]string, 0, len(ts.Fields))
for _, sf := range ts.Fields {
fields = append(fields, sf.String())
}
return fmt.Sprintf("struct %s {\n\t%s\n}", ts.Name, strings.Join(fields, ",\n\t"))
}
func (sf *ThriftStructField) String() string {
thriftType := sf.Type
if sf.IsArray {
thriftType = fmt.Sprintf("list<%s>", sf.Type)
}
return fmt.Sprintf("%s: %s %s %s", sf.ID, sf.Required, thriftType, sf.Name)
}
|
其实就是ThriftStruct按照 thrift 的语法模板,填充自己的属性字段。对于复杂类型ThriftStructField,递归调用它自己的代码生成逻辑。
1
2
3
|
struct ${name} {
${field}...
}
|
而 thrift 中其他类型,比如exception、service我们都可以进行同样的操作,识别出它的特征,生成对应的 model,再输出成 thrift 格式。
总结
Go 标准库中语言规范相关的包已经为我们封装好了解析、遍历 AST 的能力,在此基础上,再配合go/printer将 AST 输出成 Go 代码,我们就能做出很多有趣的工具,比如官方提供的go fmt、goimports,底层原理大多是魔改原始的 AST,再格式化输出成新的代码。其实我们这里反推 thrift 也是类似的流程,只不过在代码生成阶段输出的不是 Go 代码,而是 thrift 描述文件。
希望能够抛砖引玉,启发大家造出更多更好用的工(lun)具(zi)来。
参考资料