TL;DR
用 etcdfs 就可以,它能把一个 etcd 集群的 key-value 键值对,按照逻辑层级关系,映射成文件系统中的文件和文件夹,这样我们就能够用回熟悉的ls, grep, vim等工具了。
举个栗子
Kubernetes 底层使用 etcd 来存放数据,如果我们想了解具体数据的组织结构,那用etcdctl就有点强人锁男了,因为它的操作对象是一个个扁平的 key-value 键值对,我们需要脑补出其中的层次结构。但如果把整个 etcd server 挂载到本地的一个目录上,再用 VS Code 打开这个目录,那所有的数据都一览无遗,我们就拥有了一个更高阶的全貌视角:
其实 Kubernetes 存放的数据格式继承自上古时代,那个时候用的还是 etcd v2 版本,所有的数据也是根据 v2 的模型组织成了一个树形结构,到后来虽然升级到了 v3,但之前的层次结构还是遗留了下来,对于这种有逻辑层级关系的数据,用一棵文件树来表示,似乎更有可读性。
如果有兴趣,可以找一个 Kubernetes 集群,按下面的步骤,自己挂载一个来实际观察一下:
|
|
到这里为止,“怎样把 etcd 挂载到本地” 这个问题算是解答了,所用到的操作也就上面的几条命令,你也可以关掉页面了。但如果你想了解它是怎么做到的,请继续阅读…
工作原理
背景
Linux 有一个 slogan —— 一切皆文件,支撑这个 slogan 的是它背后的各种文件系统,比如常见的procfs, ext4, NFS。在这些花式文件系统之上,Linux 抽象出了一层 VFS(Virtual File System),用来对外提供统一的接口,这样上层应用就不需要关心底下挂载到底是什么文件系统了。我们拿一个读请求举例:
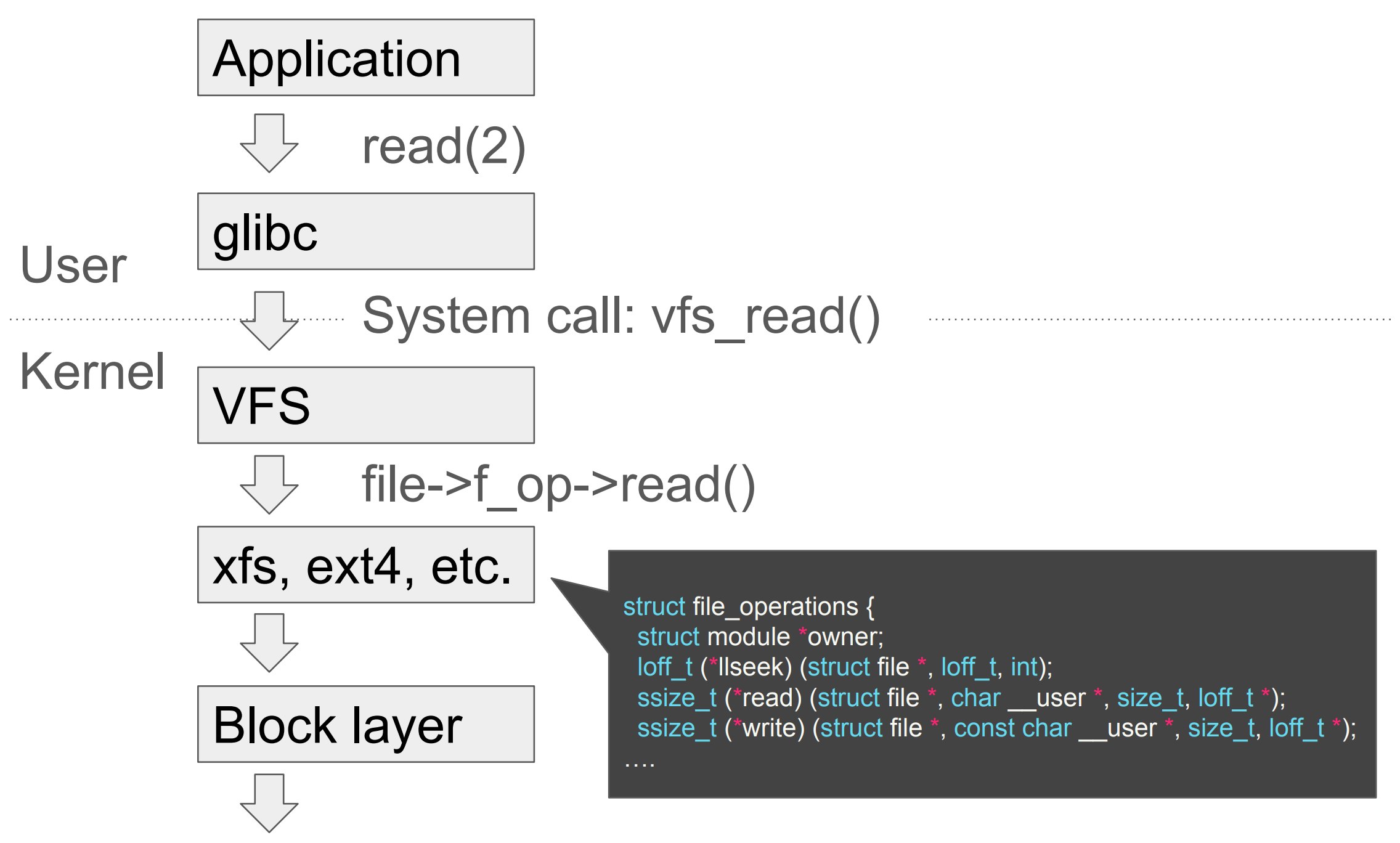
- 应用程序发起一个读函数调用。
glibc把该函数调用翻译成对应的系统调用。VFS知道具体挂载的文件系统,转而调用该文件系统的函数指针。- 不同的文件系统会有不同的实现逻辑,比如
ext4就根据inode中的元信息,去底层的块存储中寻址取值。
FUSE 文件系统
了解完上面的流程后,再来介绍另一个文件系统的实现——FUSE(Filesystem in Userspace),它在整个文件系统栈中的定位跟ext4一样,也是响应VFS的调用,只不过把该调用封装成 FUSE 协议的消息1,通过设备/dev/fuse转发出去,这样用户态的程序只要监听该设备,解析消息作出相应的处理,并再发送回去就行。借助这样的能力,我们就能够在用户态模拟出一个文件系统来。
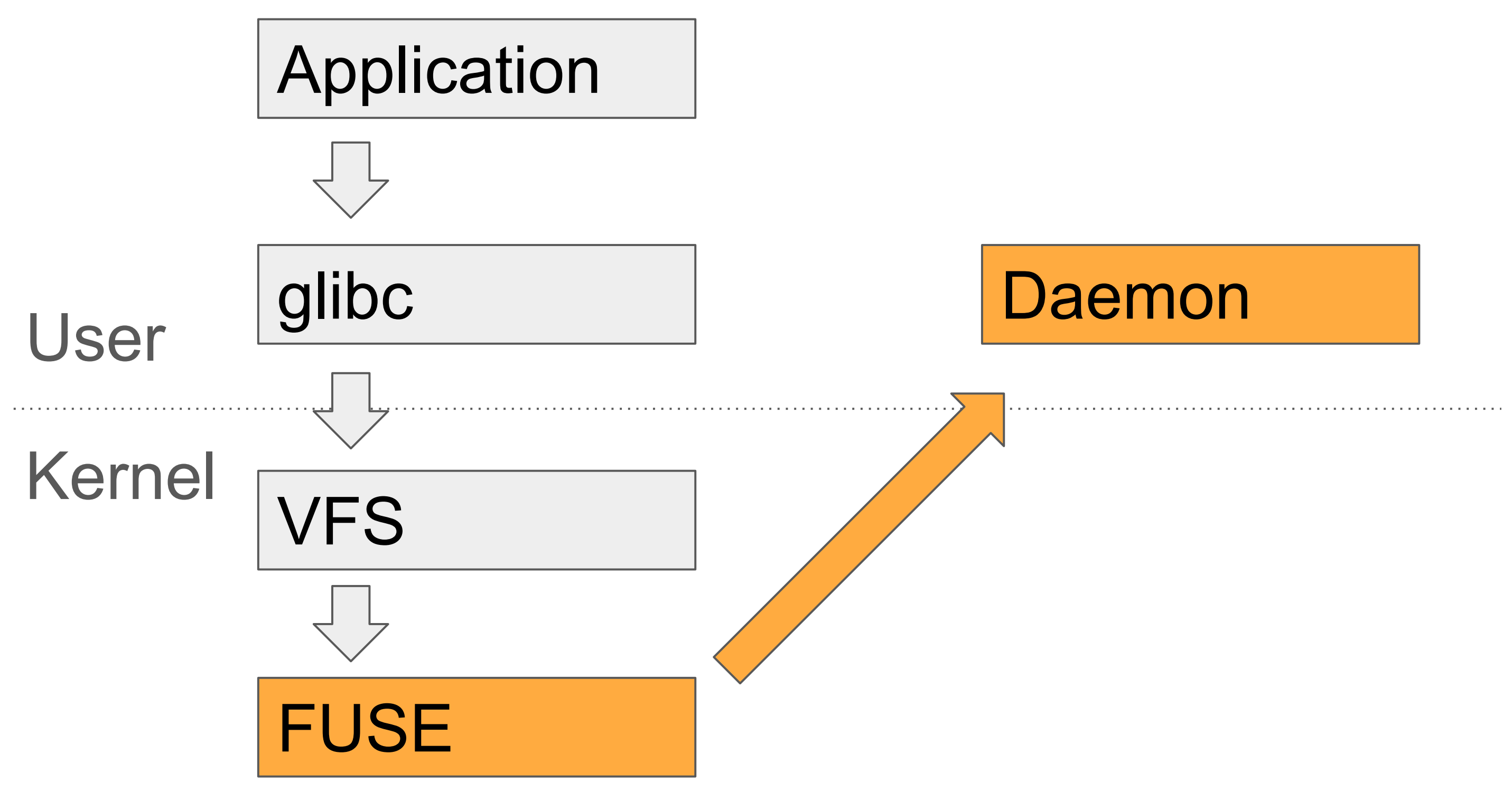
这种不依赖于底层硬件的灵活性给了程序员们无限的可能,比如将 FUSE 的请求通过 ssh 转发到远程的sshfs,再比如这里的 etcdfs,也是将文件系统的操作转化为对 etcd 的 CURD 操作🤪。
Go-fuse 库
在 Go 语言生态圈,不少大佬都对 FUSE 协议进行了封装,其中用户量最大的应该是go-fuse,它作为 FUSE 的客户端,负责与内核中的 FUSE 模块交互,读取 FUSE 请求,解析出其中的OpCode2,并转为对用户程序中相应方法的调用,然后将结果封装成 FUSE 消息返回出去。
在 go-fuse 中最重要的一个概念就是fs.Inode3,它代表了在 VFS 文件树中的一个节点,所有文件系统的操作都需要以一个fs.Inode作为操作对象。在最开始做挂载调用的时候,我们就需要创建好一个fs.Inode对象,作为后续所有操作的根节点,它的inode编号必须为1。有了根节点之后,我们就可以递归的查找它的子节点,直到找到目标操作对象。
再举个栗子,比如现在发生了unlink("/tmp/foo")系统调用,那 VFS 层首先会把目标文件名进行分段处理,在这个例子中,我们会得到三段:/, tmp, foo。其中的根节点/在挂载的时候已经创建了,所以 VFS 会以它作为起点,依次调用Lookup方法递归遍历下去:
- VFS 调用 root 节点的方法
Lookup("tmp"),拿到代表 tmp 目录的 Inode。 - VFS 继续调用 tmp 节点的方法
Lookup("foo"),拿到代表 foo 文件的 Inode。 - VFS 拿到目标节点后,调用目标节点的
Unlink()方法,实现删除操作。
当然,实际实现中,我们不可能每次都从根节点一路遍历下来,那样子性能太差了。Linux 的 VFS 层支持dentry cache ,dentry用来保存文件名和inode之间的映射,并且允许文件系统的实现者设置 cache 的过期时间。在 ext4 的实现中,该缓存被设为永不过期,而 go-fuse 则允许我们通过 EntryTimeout 来指定过期时间。
理解了 fs.Inode 的查找逻辑之后,剩下的就是在该对象上实现各种各样的方法了。因为 go-fuse 拿到一个 OpCode 之后,会用 Go 的接口断言判断一下当前的 fs.Inode 对象是否实现了该 OpCode 所需的方法,如果实现了则直接调用用户程序中的方法,否则走默认处理逻辑或者报错。
总结
etcdfs 将文件系统常用的操作(比如:open, read, write, flush)都实现了一遍,底层封装的还是对 etcd 的操作。在知道了 go-fuse 的工作原理及使用方法后,这部分文件系统相关的代码应该就不难理解了。如果你对 etcdfs 有什么反馈建议,也欢迎与我交流。