我目前的工作主要是跟IBM主机打交道,但每次向别人介绍主机时,总觉得对方很难get到它的价值。一方面是因为主机这个系统太古老,又相对封闭,它从芯片,到存储,再到操作系统都是IBM一手包办的,外界很难接触到这个系统,另一方面一直以来主机的努力方向都是希望一台机器就能满足用户高性能,高可用的需求,这跟现在用廉价机器搭建分布式集群的哲学是相对的,所以在这样的时代背景下,主机就更显得格格不入了。 我打算用这篇博客来介绍一下我所了解的主机,也顺带整理一下这些零零碎碎的知识。当然由于我并没有接受过系统的主机培训,掌握的技能都是由同事传授,外加查资料摸索出来的,所以这里如有疏漏或者描述不当的地方,欢迎指正。
历史及现状
IBM主机又称大型机(Mainframe),最早可以追溯到上世纪60年代IBM研发的S/360系统,经过半个多世纪的不断更新,IBM的主机产品线已经从当初的S/360、S/370、S/390,发展到后来的z9、z10系列,现在(2018)已经GA的最新版本是z14:

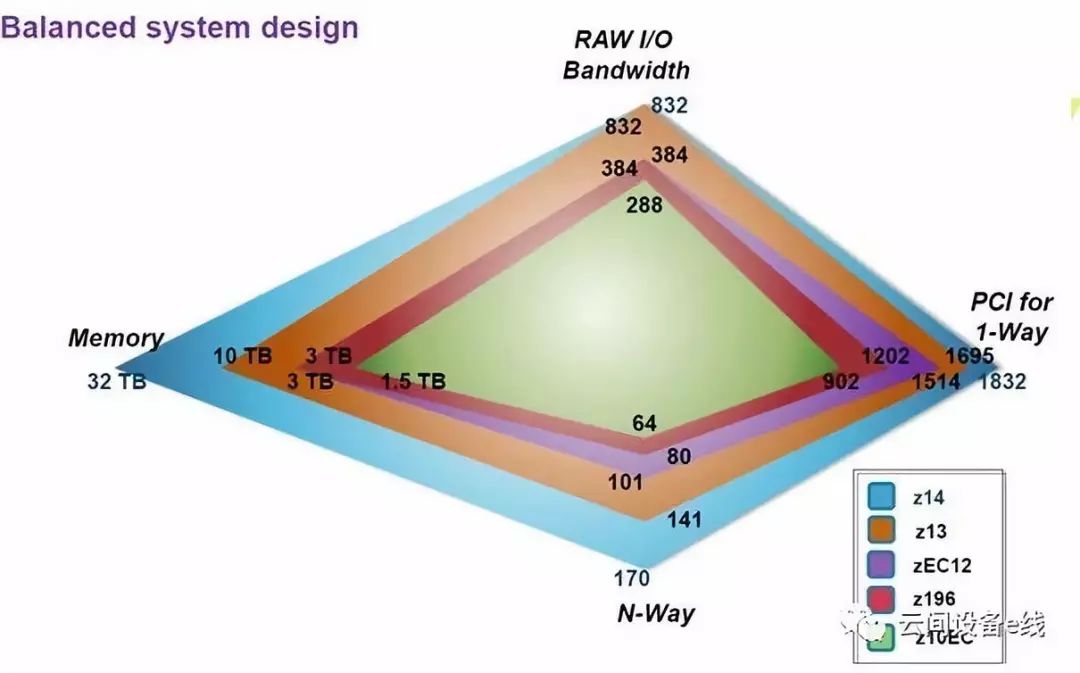
IBM主机相比于其他计算机系统,其主要特点在于它的 RAS (Reliability, Availability, Serviceability 高可靠性、高可用性、高可维护性)。它对外承诺的 SLA 是5个91,即全年停机时间不超过 5.26 分钟(2020年更新:z15的 SLA 已经达到了7个9,即全年停机时间不超过 3.16 秒)。曾经有用户反馈,在使用主机的数十年时间内,从未发生过异常停机事件。正是因为这些方面的优点和强大的处理能力,到现在为止还没有其他的系统可以替代它。但由于成本巨大(一台主机通常以亿为计价单位),使用主机系统的一般以政府、银行、保险公司和大型制造企业为主,因为这些机构对信息的稳定性和安全性要求很高。全球财富500强企业中的71%是IBM主机用户,全球企业级数据有80%驻留在IBM主机上2。在我国,从央行到工农中建四大商业银行,其核心业务平台都是跑在IBM主机上的,希望银行能给点力,早日摆脱对国外技术的依赖。
这里有一个 z14 的宣传视频,希望能给大家带来一定的感性认识:
硬件
我对硬件不是很了解,只能列举一些数据来说明主机的硬件性能(以最新的 z14 为例)3:
- 14nm 制造工艺
- 5.2GHz 主频
- 170 颗处理器
- L1 private cache 128k i, 128k d
- L2 private cache 2 MB i, 4 MB d
- L3 shared cache 128 MB / chip
- L4 shared cache 672 MB / drawer
- 支持 32TB 内存
- 支持8000个虚拟机
- 可以横向扩展(scale out)到2百万个Docker容器
主机的一个鲜明的特色就是采用了中央处理器(CP)与系统辅助处理器(SAP,System Assist Processor)组成,其所采用的CP既不是IBM自家的POWER,也不是x86,而是一个“IBM独立自主”的,基于z/Architecture主机架构而开发的处理器,其采用复杂指令集架构(CISC),有一些复杂指令负责微码(millicode)执行,也有一些被分解为类似于RISC的操作,因此虽然在总体架构上是CISC,但也兼具了RISC的优点。4
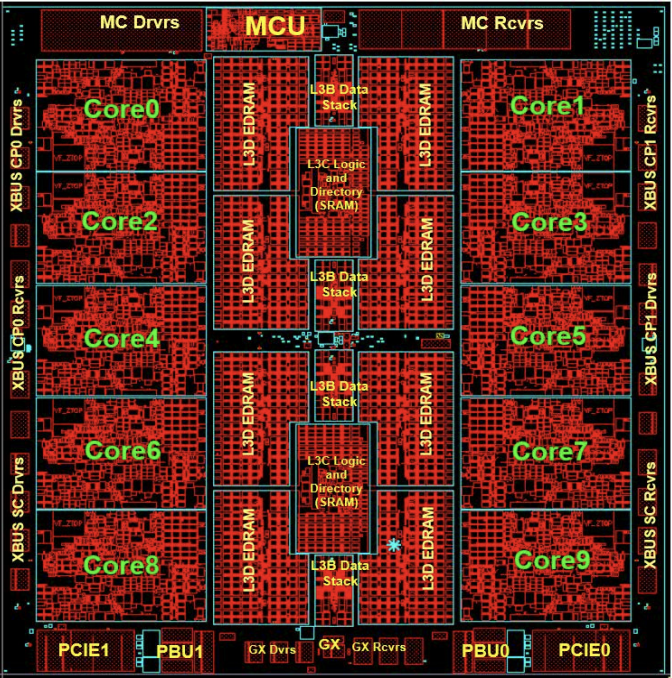
除此之外,主机还将一些常用的软件模块用硬件实现了,比如硬件压缩卡(zEDC),排序指令,加密指令,向量运算指令等。这些原本需要通过软件模拟来实现的功能,直接有了对应的硬件支持,这种霸气的设计方法,对年轻的我造成了巨大的冲击。
操作系统
主机上的操作系统叫做z/OS,z代表终极的意思。我们需要通过一个叫3270的终端来连接它,由于这个终端的配色以绿色为主,所以我们又叫它小绿屏。这个小绿屏实在太显眼了,有同事曾在宜家的收银台一眼认出来过,不过我很好奇,宜家的收银员难道还要懂怎么操作底层的z/OS?
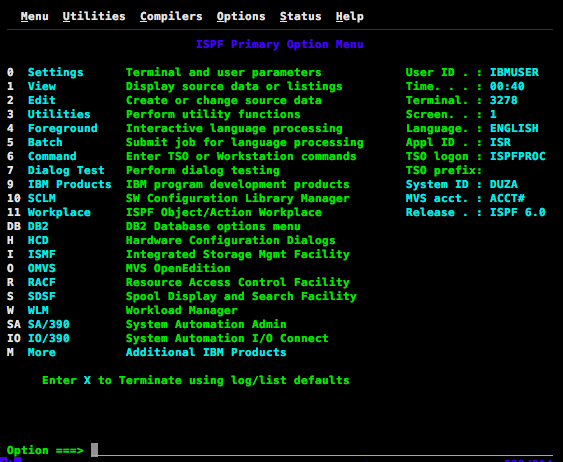
与z/OS的交互跟现代系统很不一样,它是一个用文本画出来的界面(如上图),可以在界面的不同位置输入不同的命令来完成不同的功能。比如这里我可以在Option ===>那一栏通过输入menu之前的数字或者字母来进入相应menu。另外的一些功能则需要通过fn键来完成,比如F3是返回,F8是向下滚屏,F7是向上滚屏。
文件系统
在z/OS里,文件叫做DataSet,它也有好多种类,其中最常见的是这3种:
- Sequential - 有点类似数据结构里的
Array,按顺序排放的数据集,顺序读写效率高,但随机读写效率就不行了。 - Partitioned - 有点类似文件夹的概念,它里面的数据集叫做member。
- VSAM - 有点类似
map,支持通过key来建立访问索引。
同样与现代的流式文件系统不一样,DataSet是基于record的,每次读和写都只能以record为单位,这里就有一个很容易碰到的坑,如果一次写操作的数据量超过了一个record的长度,那超过部分会被截掉,并且没有任何提示的,如果总的写入量超过了这个DataSet创建时分配的大小,那超过部分也会被无情的截掉😪。所以每次创建DataSet的时候,我们都要预先设好它的各种属性(这其中的大部分细节都被现代的文件系统用inode给隐藏起来了)。
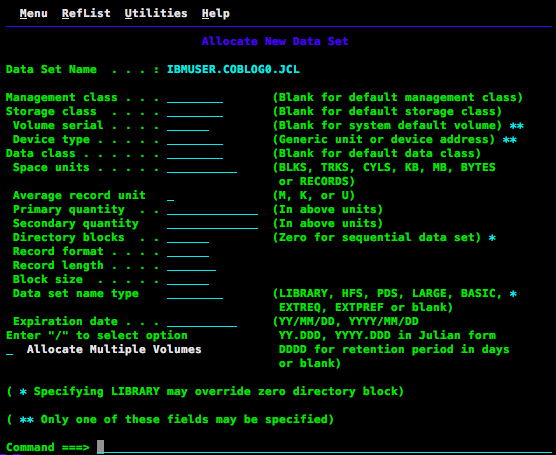
DataSet的名字用点(.)作为分隔符,一般来说整个z/OS的文件系统都是扁平化的,即不会出现一个文件夹里面嵌套好几层文件夹的情况,为了方便在这种结构下组织文件,z/OS支持用?或者*来模糊匹配一部分文件路径。还有一点值得提及的是,带单引号(')的DataSet是绝对路径,不带单引号的是相对路径,相对于当前用户的HOME(z里面叫HLQ),所以如果我说要访问COBLOG0.JCL,其实我访问的是'MYUSER.COBLOG0.JCL'。
Migrate是另一个有趣的特性。z/OS会定期Migrate掉长期不用的DataSet,这些DataSet会被移到一个容量比较大的Tape上,以节约当前文件系统的空间,当下次需要使用这个DataSet的时候,要先把他Recall回来。这就有点类似Page Cache和磁盘的关系,Page Cache总量就那么大,只能用来存热点数据,那些冷数据就让它呆在磁盘,到用的时候再加载进来好了。
向后兼容性
z/OS的向后兼容性简直可以用典范来形容5,据说一个上世纪80年代编译出来的程序,在现在的主机上依然可以运行。但也正是这种严苛的向后兼容性让主机背上了沉重的历史包袱,比如主机上使用的字符集是EBCDIC,它跟ASCII是不兼容的(比ASCII标准出来的要早)。用现在的眼光看,EBCDIC是一种奇怪的编码格式,它的I和J、R和S是不连续的。这个格式源自于打孔卡时代,那个时代,IBM是计算机领域的头号玩家,所以他们制定的编码标准也希望能与自己的打孔卡相兼容5。
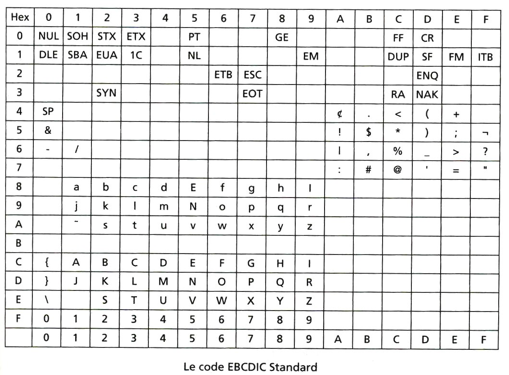
这个在当时看来无比正确的决定却给现在的我们带来无数的坑,在移植x86平台的程序到主机时,最大的麻烦就在于字符集的处理。但这种备受开发人员吐槽的向后兼容性却很受客户的欢迎,因为客户的诉求就是稳定可靠,他们希望应用程序开发完了之后,不应该因为操作系统的升级而需要重新开发,从这点也可以看出IBM客户至上的理念。
其他组件
z/OS是一个非常庞大的系统,它里面包含了非常多的组件,其中大家比较熟知的可能有CICS和DB2。这里,我只介绍几个我比较熟悉又非常基础的组件:
-
USS - z/OS Unix System Services,这是IBM开发的一个兼容POSIX的子系统,它给其他Unix平台的程序在z/OS上的运行带来了可能性。一家叫Rocket的软件公司就是通过给z/OS移植外界的应用程序而起家的。有了USS的支持后,我们就可以通过
ssh登上z/OS,用bash操作一些原本需要小绿屏才能完成的操作了。 -
JES - Job Entry Subsystem,在小绿屏上的操作其实是叫做前台操作,这对一些简单或者需要人机交互的任务来说很有必要。但如果一个任务需要长时间的运行,肯定不能让用户一直在前台干等,所以z/OS里有JES这个子系统,它可以让用户将需要长时间运行的程序通过Job的形式提交进来,然后在后台跑这个Job,并通知用户最终的结果。这里提交Job的形式就是写一个
JCL(Job Control Language),它提供了类似shell脚本的功能,可以让用户使用各种循环及判断语句。这里是一个简单的批处理JCL:1 2 3 4//MYJOB JOB ,NOTIFY=&SYSUID //STEP1 EXEC PGM=MYPGM //STEP2 EXEC PGM=MYPGM2 //STEP3 EXEC PGM=MYPGM3 -
FTP - z/OS上的FTP功能相当强大,它的操作对象不仅可以是DataSet,也可以是USS下的文件系统,甚至还可以向JES提交Job,向DB2提交SQL语句。因此,在我们的一个项目中,为了使Node.js能与z/OS交互,我们用Node.js封装了FTP的这些特性,并开源出来一个库:z/OS Node Accessor,希望它能成为Node.js社区与z/OS连接的桥梁。
总结
写了半天才发觉我还只介绍了主机的冰山一角,主机经过半个多世纪的发展,它的复杂程度远远不是一篇博客就能介绍完的。所以这只能算是一个入门级别的介绍,希望读完之后能让你对主机有个大致的了解。