迭代器(iterator)是一种常见的设计模式,它屏蔽了复杂的底层结构,给上层抽象出了一个简单的遍历接口。在 LevelDB 中几乎所有的读操作都是通过迭代器来完成的,使用者不需要关心底层数据源 MemTable/SSTTable/Block 等等的内部细节。
1. 概览
当我们谈迭代器时,我们其实谈的是这个接口:
|
|
用户只需要知道如何使用这个接口就可以了,底层的数据结构会适配这个接口,将内部内容暴露出来。在 LevelDB 中,大概有 7 个类实现了这个接口。
2. 具体实现
目前的实现中,可以大致分为原子类和组合类:
2.1 原子迭代器
原子迭代器直接与底层数据结构交互,它负责 key 的寻址,value 的解析等繁杂的工作。
2.1.1 MemTableIterator
MemTableIterator 是对内存 SkipList 的简单封装。这个封装并不复杂,复杂的是 SkipList 的实现,但这不是本文的重点,这里不再细说。
2.1.2 Block::Iter
Block::Iter 是对 SST 文件里面的 Block 的封装,所以它需要去理解 Block 序列化后的结构:
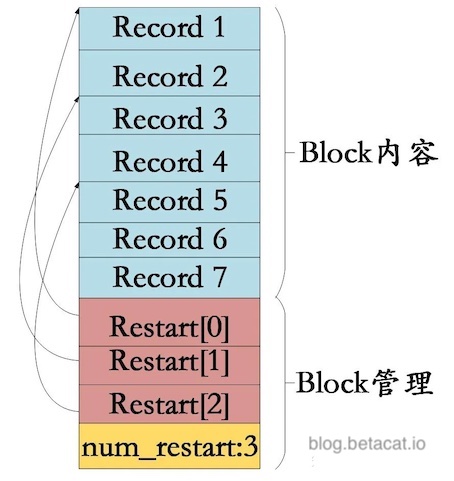
无论是 Data Block 还是 Index Block,他们的物理布局都是一样的:
- 最后的 4 字节记录了这个 Block 中的 Restart Point 个数。
- 再往上则是一个有序的 Restart Point 列表,列表的每一项代表一个 4 字节的 offset,指向具体的 Record。
- 最上面一层是一堆变长的 key/value 对,其中的 key 采用了前缀压缩法保存。对于 Data Block,value 保存的是用户传入的 value。而 Index Block 的 value 保存的是该 key 对应的 data 的位置,也就是
BlockHandle。
了解了布局,我们重点关注这个迭代器的寻址代码:
|
|
Seek流程分成了两阶段搜索,首先在有序的 Restart Points 数组里面二分搜索找到最后一个小于 target 的 Restart Point,这一阶段的步长单位至少是 4KiB,能快速定位到一个粗略的位置;然后再从该位置线性搜索找到第一个大于等于 target 的 key,这一阶段的步进单位是 key/value 对(因为每段区间里的 key 是前缀压缩保存的,所以它只能从头开始解压边搜索),这算是个典型的稀疏索引搜索流程。Restart Point 的步长取值需要权衡一下:
- 较大的步长会带来更高的存储压缩比,但相应的读取开销会变大,因为它需要从压缩的起点开始挨个解码,才能搜索到想要的 key。
- 较小的步长有助于
Seek请求,但会导致索引变大,影响BlockCache的命中率,从而触发更多的 IO。
其他接口的实现不再赘述。
2.1.3 LevelFileNumIterator
LevelDB 中 0 层以上的文件都是有序且互相不重叠的,所以Version::files_[1..6]其实是个有序数组。在这个数组之上,LevelDB 封装出了另外一个原子迭代器——LevelFileNumIterator,用来负责对高层文件之间的迭代。
它的Seek 方法就是一个常规的二分搜索过程,细节可以参考代码。
2.2 组合迭代器
现在,我们具有了读取内存和磁盘文件的能力,就可以将它们花式的组合起来,以适应不同场景下的读取需求。
2.2.1 TwoLevelIterator
TwoLevelIterator 是一个比较抽象的组合,它的寻址思想跟上面的Block::Iter 比较类似:
- first_level_iter 使用大步长的方式快速寻址到一个粗略的位置
- 然后 second_level_iter 再在小范围内寻址
|
|
它的使用场景主要有两个——针对 SST 文件内的迭代器和针对每一层文件间的迭代器:
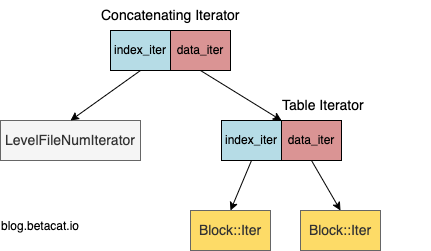
2.2.1.1 SST Table Iterator
上面的 Seek 代码以Table::NewIterator的实现为例:
- 通过 Index Block 的迭代器
index_iter_快速定位到可能的 Data Block - 读取这个 Block,并初始化出对应的迭代器
data_iter_ - 再在
data_iter_上递归寻址
这里用到的两个迭代器都是原子迭代器,即上面的Block::Iter。
2.2.1.2 Concatenating Iterator
而针对每层文件的迭代器ConcatenatingIterator则将index_iter_初始化为了原子迭代器LevelFileNumIterator。由它驱动,将多个文件串联起来,按需加载对应的文件,将data_iter_设置为对应的文件迭代器Table Iterator,再按上面的流程递归寻址。这里就形成了一个嵌套的迭代器链:
2.2.2 Merging Iterator
MergingIterator 顾名思义就是一个将多组局部有序、且可能重叠的迭代器合并成一个全局有序的迭代器。它的主要用途:
- Compaction——对上下两层文件进行合并,输出一个有序的新文件
- DBIter——对全局所有 key/value 存储点进行合并,数据源包括 MemTable/Immutable MemTable/Level 0/Level 1~7 SST,对用户输出一个全局有序的迭代器
有点算法基础的同学都知道,MergingIterator 的实现就是一个归并排序,只不过这里是个多路归并——每次从迭代器列表里取最小值对外输出即可:
|
|
目前的
FindSmallest使用了暴力的遍历法,但 RocksDB 里面已经改成了最小堆来降低时间复杂度。
2.2.2.1 Range Scan 的实现
这里引申出一个话题,我们可以利用这个归并排序来实现一个范围查询(Range Scan)。LevelDB 只暴露了点查相关的 api,范围查询则需要通过不断调用迭代器的Next方法,来获取下一个最小值:
|
|
2.2.3 DBIter
DBIter 是个集大成者,直面用户。用户可以调用通过它来遍历整个数据库的 key/value 对,本质上它是对底层MergingIterator输出的过滤:
sequence_字段保证了它不会读到这次事务开始后的变更,实现了一个 Snapshot Read。FindNextUserEntry/FindPrevUserEntry方法用来跳过当前 iter 所指向的删除记录,或者被新值覆盖过的旧记录。
2.2.3.1 InternalKey
LevelDB 中物理存放的 key(InternalKey) 并不是用户指定的 key(UserKey),它在 UserKey 后面添加了 9 字节内容,用来标识这次变更的逻辑时间戳(Sequence Number)和类型(值类型或者标记删除的墓碑),结构布局如下:
|
|
对这个复合类型进行排序的规则是:
- Dncreasing user key
- Decreasing sequence number
- Decreasing type
2.2.3.2 过滤
比如说,有这样几个 InternalKey(用冒号:将 3 个字段进行了分割),他们排序后的布局是这样的:
|
|
当初始化一个 sequence 为3的 DBIter 后,我们只会遍历到(key_c:4:0)这条记录,因为:
- 对
key_a来说,它的两次操作 sequence 5/6 比 DBIter 初始化时的 3 更新,因此他们对本次遍历不可见。 - 对
key_b来说,它的两次操作(1/2)虽然早于 DBIter 开始的时间,但它的最后一次操作是删除,因此也应该对用户不可见。 - 对
key_c来说,取最新的变更key_c:4:0对应的值返回用户。
这样过滤后,就将 LevelDB 内部的实现细节屏蔽了,而给用户返回了一个最新且一致的结果。
2.2.4 其他迭代器
除了上面几个比较重要的迭代器外,LevelDB 还封装了几个辅助迭代器:
EmptyIterator: 一个携带错误状态的空迭代器。作者估计是为了统一上层的错误处理的逻辑,但我觉得更清晰的错误处理方法,是在迭代器的工厂方法里直接将错误返回出来,而不是等到在使用的时候,才发现这个迭代器在一开始创建的时候就失败了。IteratorWrapper: 更好的名字似乎应该叫 CachedIterator?因为它将底层迭代器的 key() 和 valid() 方法的结果缓存了下来,这样既能减少对虚函数的调用(底层迭代器是个接口),同时又增加了 cache 的局部性(不需要在实例和虚表之间跳来跳去)。
总结
本文自底向上的简要介绍了 LevelDB 中的各种迭代器,并由此引出了相关的数据结构,尽可能的覆盖了 LevelDB 中的各种概念,希望能让读者对 LevelDB 有个更全面的了解。