NFS 协议经过20多年的发展,已经变得非常复杂,本文以 mount 过程中发生的交互为切入点,带大家走进 nfs,走近科学…
Mount 可以类比于其他协议中的握手过程,大家先拉通对齐一下,商量好以后沟通过程中要用到的一些参数。
NFS v3 和 v4 的 mount 过程完全不同,简直可以用“两种不同的协议”来形容。下面分别描述:
V3 挂载
V3 责任划分明确,一个 mount 过程涉及到好几个组件,我们可以通过rpcinfo -p查看到他们各自监听的端口:
|
|
这里的第一列代表一个服务的标识编号;第二列代表该服务所支持的版本号,可以看到在我的测试机器上nfs同时支持v3、v4两种模式;第三列代表支持的传输协议;第四列代表监听的端口,这里除了portmapper外,其他的端口几乎都是随机值;第五列代表人眼可读的服务名称。
首先需要介绍下入口服务portmapper,它一般监听在111端口,起的作用有点类似现代的 DNS 服务——客户端首先连上它,询问nfs、mountd、nlockmgr等服务监听的端口,有了端口号后才能与对应的服务打交道。话不多说,抓包看请求:
1. Portmap

这是mount刚开始的几个rpc call,大致流程是这样的:
- Client 向
portmapper询问nfs服务(100003)监听的端口portmapper回复8800
- Client 向
nfs发送一个NULL请求,用来测试对方服务是否能正常响应nfs响应
- Client 向
portmapper询问mountd服务(100005)监听的端口portmapper回复8801
Client 拿到了各服务的地址(端口)后,就可以开始对话了。它首先告诉mountd需要挂载的目录:
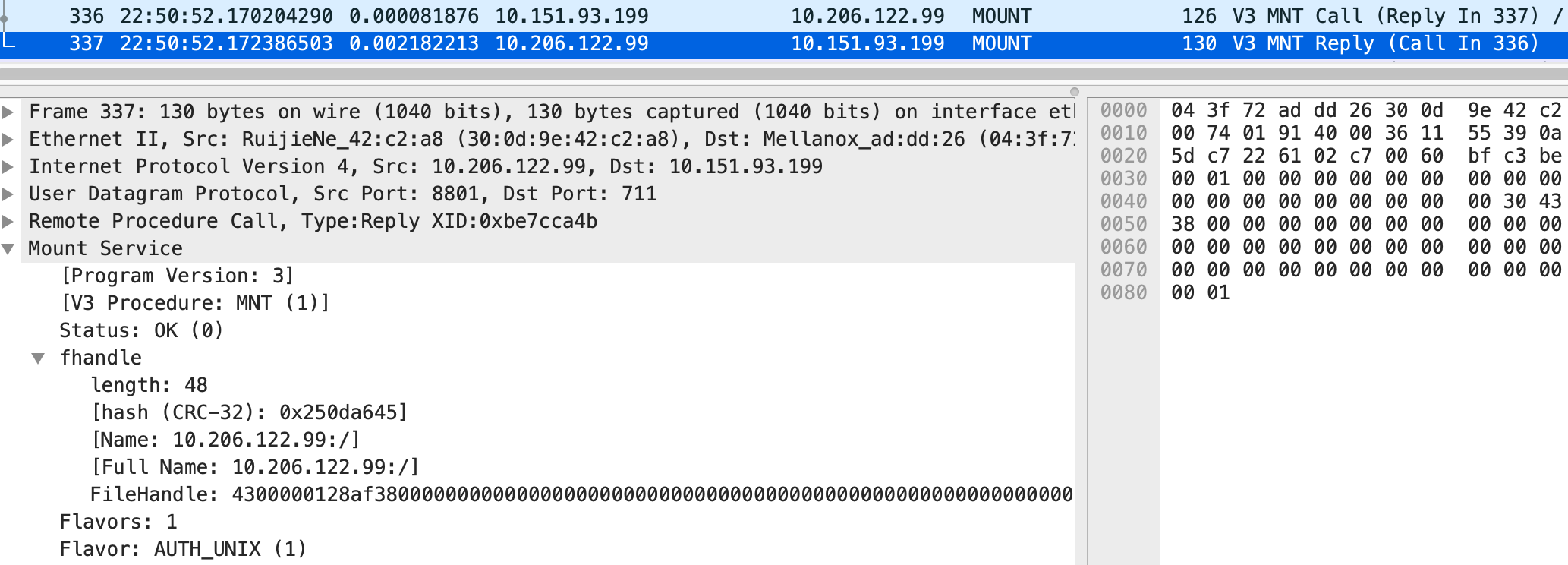
mountd在回复中则返回了根目录的FileHandle,这是一个48字节的字符数组(上限是64字节),用来唯一标识一个文件或目录。Client 并不会解析它,而 Server(这里用 Ganesha) 则会在其中编码进 Ganesha 的版本号,FS ID,Inode 等信息。
2. FSINFO
Client 从mountd中拿到根目录的FileHandle之后,一切都有据可循了,之后的操作都会直接跟nfs服务打交道。
首先用刚刚拿到的根目录的FileHandle,调用FSINFO获取该文件系统的静态信息:
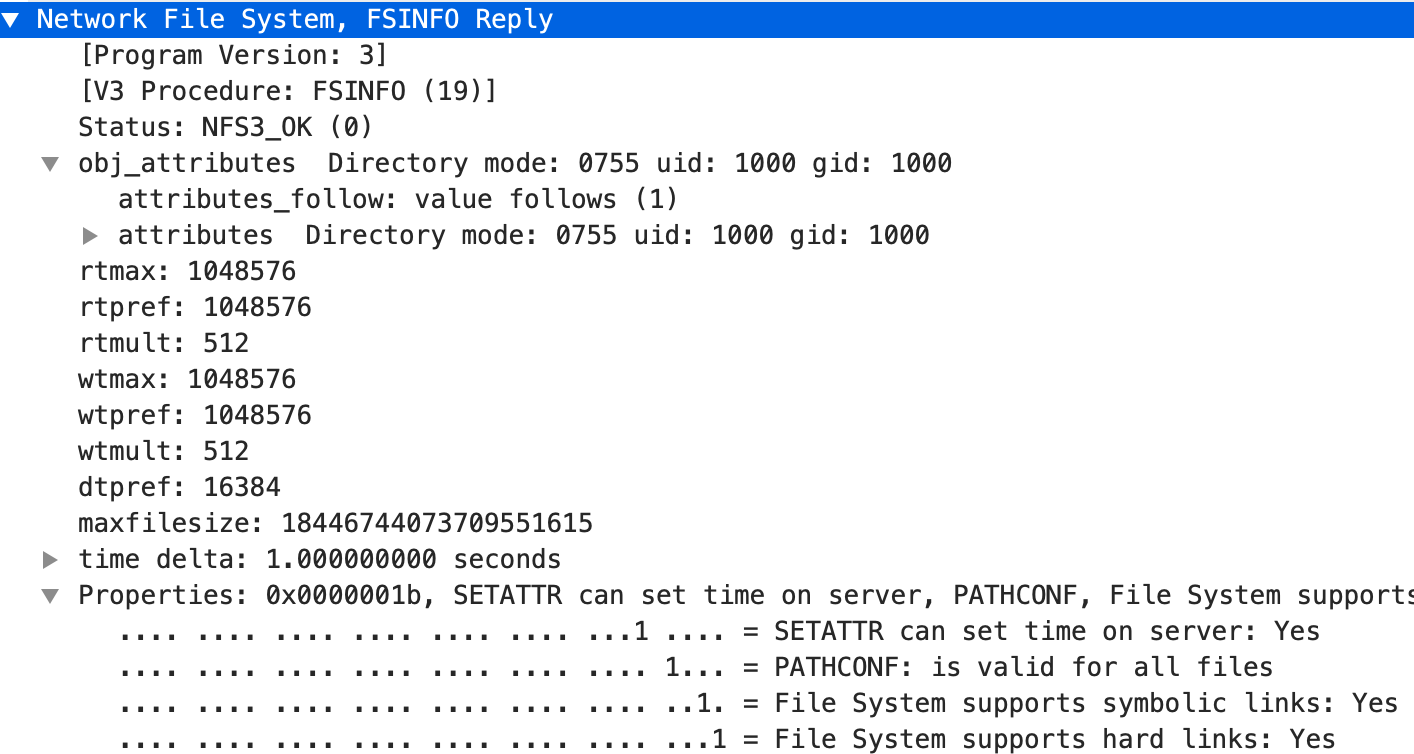
Server 返回的信息包括该 Server 所支持的文件读写时最大 IO 大小、一次readdir推荐大小、文件最大长度、以及是否支持软硬连接等能力。
3. PATHCONF
PATHCONF主要用来满足pathconf系统调用的请求,它返回了包括文件名最大长度、最大链接数、是否大小写敏感等信息。
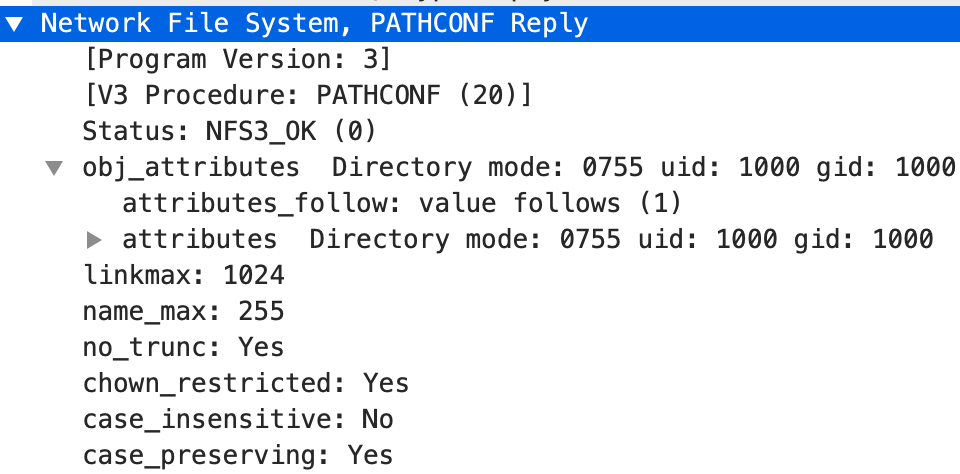
至此,Client 已经拿到了所有信息,挂载就成功了。
V4挂载
V4 相对于 V3 主要增加了Compound语义和状态的支持。在mount过程中前几个 rpc 可以理解为构造状态的种子信息。
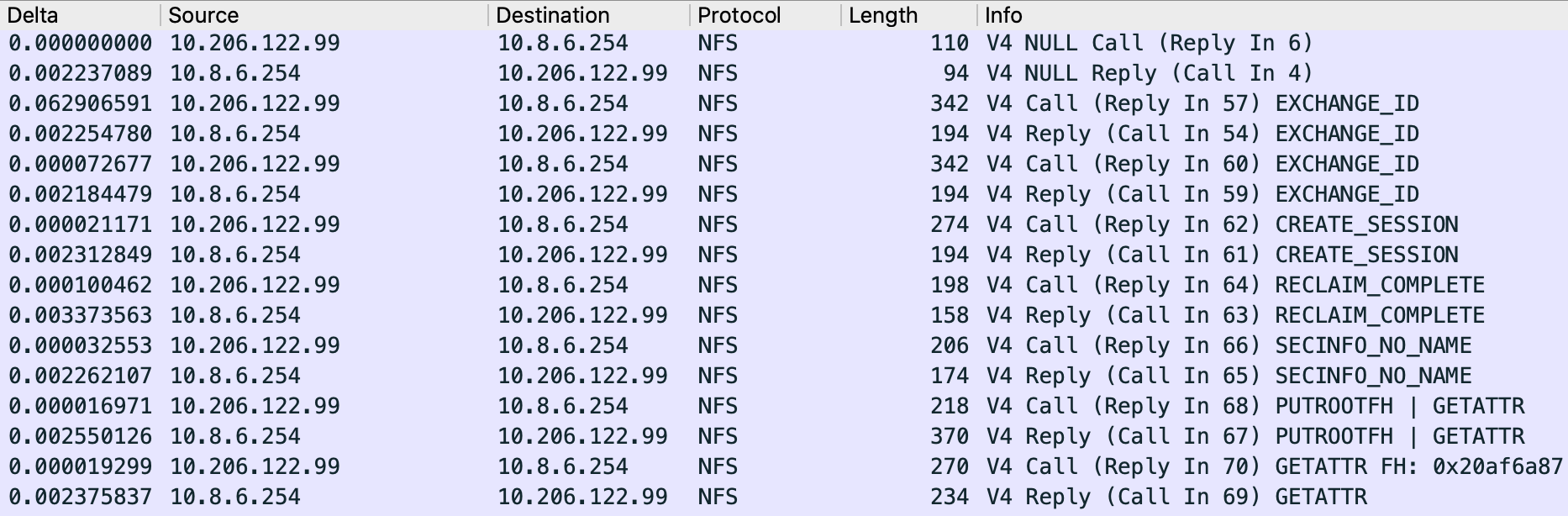
1. EXCHANGE_ID
顾名思义,这一步用来交换双方的 id,主要用来索引状态信息。
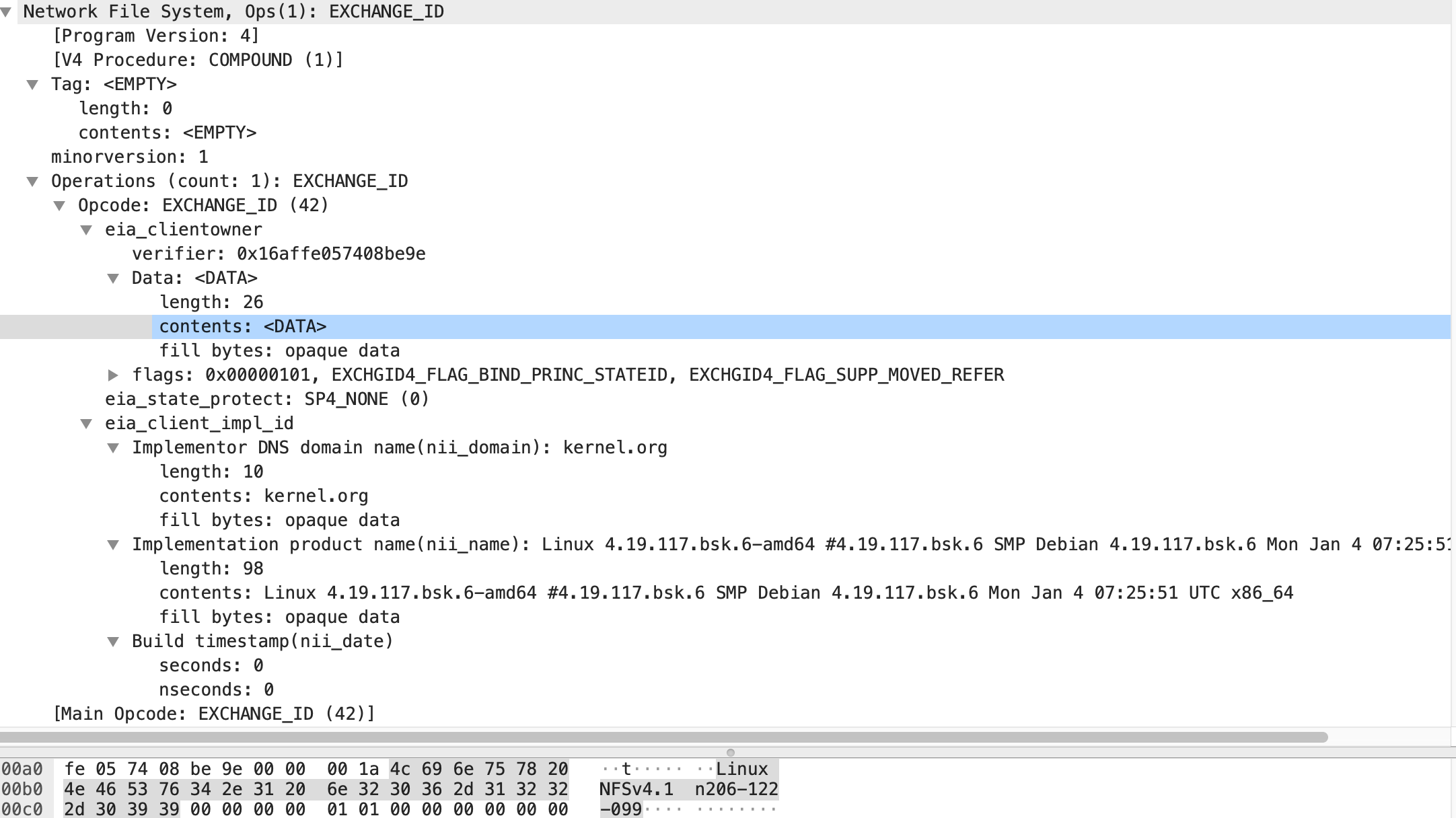
Client 提供的信息有一串 verfifier(用来标识重启)、ownerid(用来标识机器)、自己的内核版本、DNS Domain 等。目前 Ganesha 的实现中,它主要根据 ownerid、pnfs flags、server ip 的 hash 值生成一个 client id。
2. CREATE_SESSION
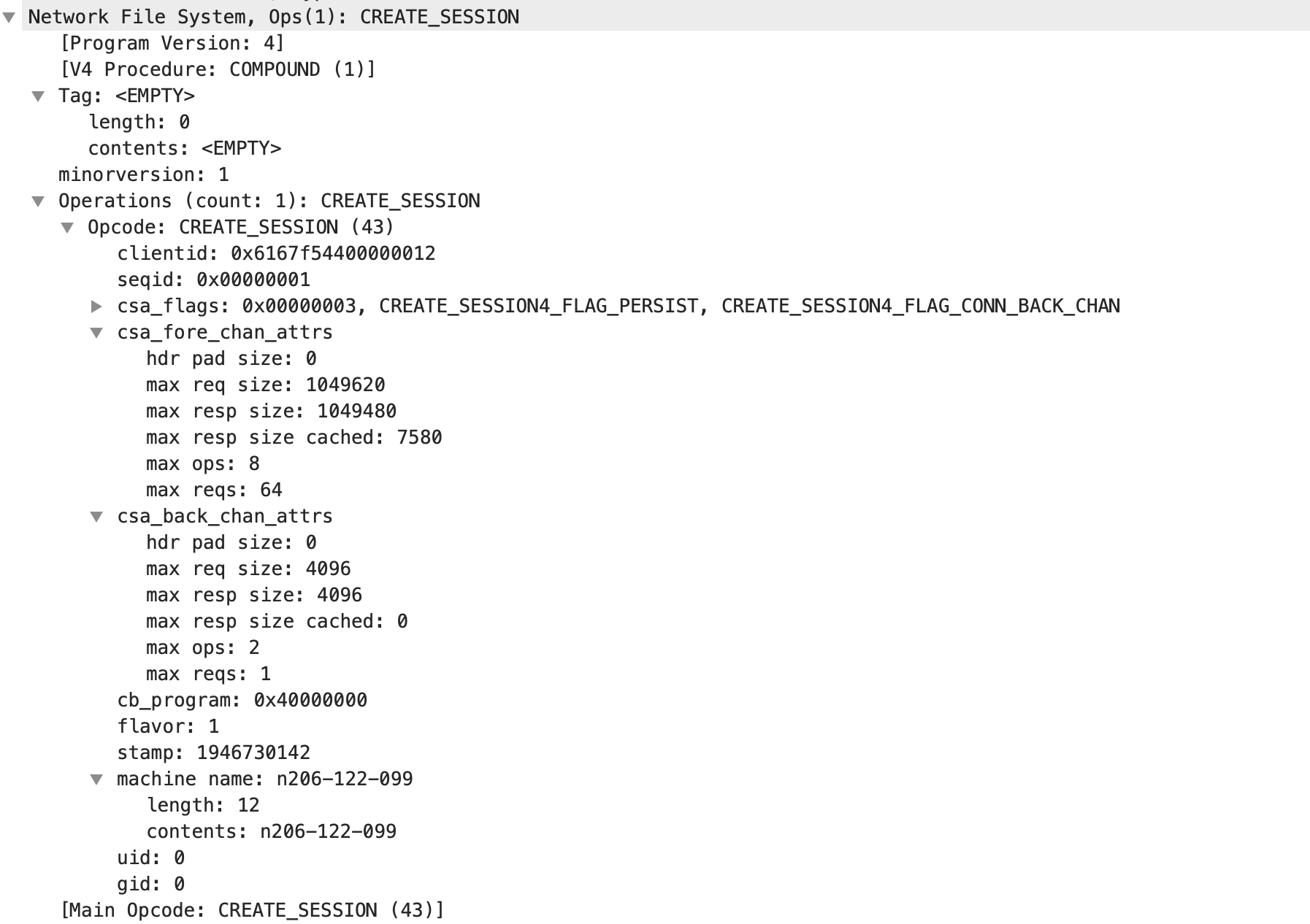
这一步就是客户端发起建立会话请求,通过此请求告知会话中使用的读写块大小等信息,会话一旦建立就会一直保存到umount或者服务器重启为止。
Session 的一个主要用途是用来确保请求的幂等性(Exactly Once Semantics),即 session id + seq id 可以唯一标识一个请求,从而缓存该请求的处理结果,以便 Client 重试。
3. RECLAIM_COMPLETE
主要是 Server 重启后,Client 恢复完状态后发起,不太了解细节…
4. SECINFO_NO_NAME
Client 将不使用任何认证信息。
5. PUTROOTFS | GETATTR
在 NFS 中,文件对象都通过FileHandle来标识,在最开始的时候,我们并不知道任何对象的FileHandle,所以 NFS 提供了PUTROOTFS这个 op ,实现了类似 V3 协议中的mount请求,用来获取Root FileHandle。
在 V4 协议中,所有的 op 都封装在一个Compound里面,一般每一个Compound里都有个设置当前上下文的 op —— PUTROOTFS(不带参数)或 PUTFH(带FileHandle参数),表示之后的 op 都操作在FileHandle这个对象上。
还以 mount 过程中的这个请求为例:
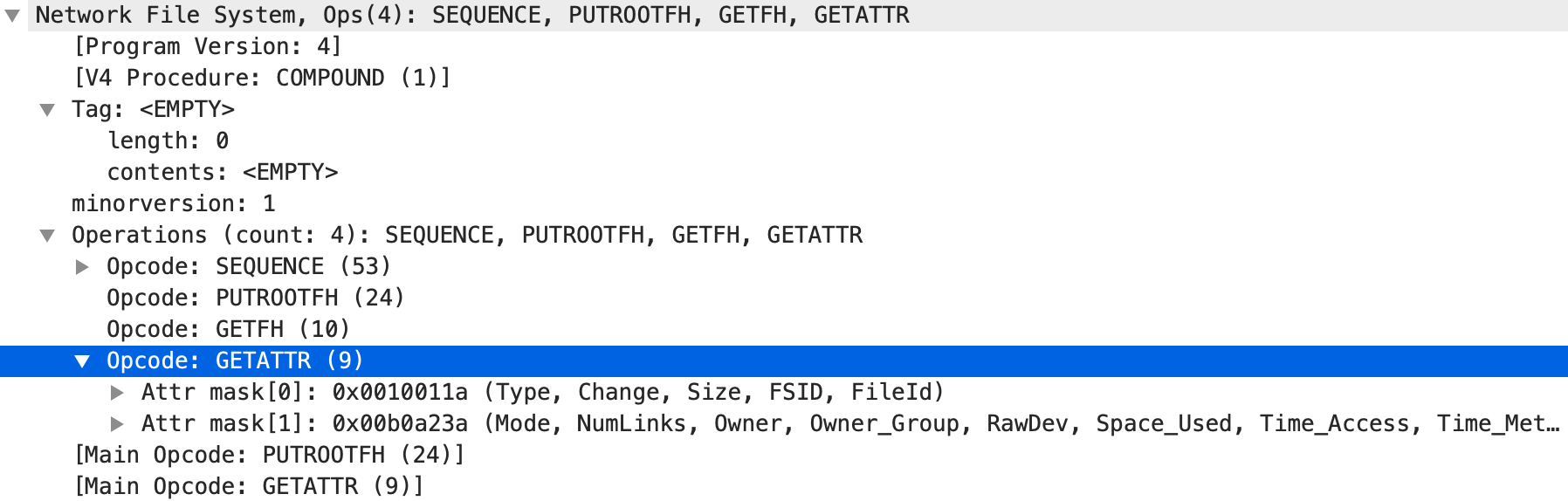
这个请求的Compound中包含了 4 个 op:
- 标识请求的 session id 和 seq id
- 将当前
FileHandle设为Root FileHandle - 返回当前
FileHandle,即Root FileHandle给客户端 - 通过
GETATTR获取当前FileHandle的属性,包括 Inode, Type, Mode, Owner 等信息
6. 若干连续 GETATTR
Client 从上一步的第3个 op 中拿到Root FileHandle之后,就可以对它进行一系列的GETATTR操作,包括获取它的最大文件大小、读写大小、是否支持软硬链接等信息。
Compound真的用起来了吗?
几乎没有。
Compound是一个很好的设计——请求流水线化,但由于 POSIX API 设计的过于底层,以及 Kernel 中实现的问题,一次Compound中有效负载的 op 很少,几乎只有一两个,比如用户要读取/home/Bob/.bashrc文件,那 Kernel Client 会构造出好几个 rpc 请求:

但事实上,NFS 协议完全支持更高效的流水线写法,即将这些主要的 op 都封装在同一个Compound中,这样从原来的 5 次 rpc 调用转为了 1 次 rpc 调用,大大节省了网络延时的开销。有一个在用户态实现的简易版 nfs client,就构造出了这样的Compound,这不仅简化了代码处理流程,也提高了 IO 效率。

Kernel Client 可能会做一些复杂的缓存,来减少这些 rpc 调用。但在大量小文件的场景下,Kernel 的缓存会频繁失效,比如git clone 7w 个小文件的 Kernel 代码,我就观察到非常多元数据的重复查询,而且每个元数据变更的请求都要同步持久化(相对而言,本地文件系统采取异步回写,批量提交的模式),这么多 rpc 请求也是 nfs 在大量小文件场景下比块存储慢的原因之一。
有人在用户态实现了一个支持构造高负荷Compound的 NFS Client,将大量小文件场景下的读写性能提升了 5~103 倍,有兴趣的可以参见这篇论文。
总结
本文以 mount 握手过程为抓手,介绍了几个常用的 nfs op,以助大家打通底层逻辑,并以 Compound为例,输出了自己的思考,更多 op 细节需要大家去查阅 rfc 文档,形成闭环。如有错误,欢迎指正:)