Raft是近年来比较流行的一个一致性算法。它的原理比较容易理解,网上也有很多相关的介绍,因此这里我就不再啰嗦原理了,而是打算以raft在etcd中的实现1为例,从工程的角度来讲讲这个算法的一个具体实现,毕竟了解原理只算是“纸上谈兵”,离真正能把它应用起来还有很长一段距离。
如果你还不熟悉raft,这个经典的动画演示、它的论文以及这个lecture可能会对你有帮助。或者你也可以直接观看下面的视频,这是我作的一次技术分享,讲的是etcd中raft模块的源码解析。说句题外话,很多Conference和Meetup都会把视频录像上传到YouTube上,YouTube简直就是程序员的衣柜,每逛一次都有新收获。
Overview
Etcd将raft协议实现为一个library,然后本身作为一个应用使用它。当然,可能是为了推广它所实现的这个library,etcd还额外提供了一个叫raftexample的示例程序,向用户展示怎样在它所提供的raft library的基础上构建出一个分布式的KV存储引擎。
在etcd中,raft作为底层的共识模块,运行在一个goroutine里,通过channel接受上层(etcdserver)传来的消息,并将处理后的结果通过另一个channel返回给上层应用,他们的交互过程大概是这样的:
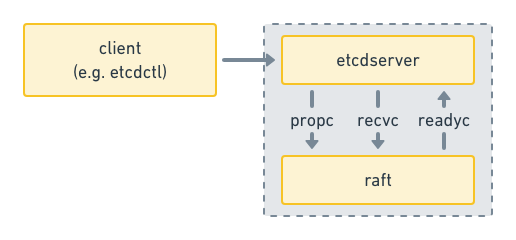
这种全异步的交互方式好处就是它提高了性能,但坏处就是难以调试,代码看起来会很绕。拿etcd举例,很多时候你只看到它把一个消息push到一个slice/channel里面,然后这部分函数调用链就结束了,你无法直观的追踪到,到底是谁最后处理了这个消息。
Code Breakdown
我们来看一下这个raft library里面都有哪些文件:
|
|
下面按功能模块依次介绍:
raftpb
Raft中的序列化是借助于Protocol Buffer来实现的,这个文件夹就定义了需要序列化的几个数据结构,我们先从Entry和Message开始看起:
Entry
从整体上来说,一个集群中的每个节点都是一个状态机,而raft管理的就是对这个状态机进行更改的一些操作,这些操作在代码中被封装为一个个Entry。
|
|
- Term:选举任期,每次选举之后递增1。它的主要作用是标记信息的时效性,比方说当一个节点发出来的消息中携带的term是2,而另一个节点携带的term是3,那我们就认为第一个节点的信息过时了。
- Index:当前这个entry在整个raft日志中的位置索引。有了
Term和Index之后,一个log entry就能被唯一标识。 - Type:当前entry的类型,目前etcd支持两种类型:EntryNormal和EntryConfChange,EntryNormal代表当前Entry是对状态机的操作,EntryConfChange则代表对当前集群配置进行更改的操作,比如增加或者减少节点。
- Data:一个被序列化后的byte数组,代表当前entry真正要执行的操作,比方说如果上面的
Type是EntryNormal,那这里的Data就可能是具体要更改的key-value pair,如果Type是EntryConfChange,那Data就是具体的配置更改项ConfChange。raft算法本身并不关心这个数据是什么,它只是把这段数据当做log同步过程中的payload来处理,具体对这个数据的解析则有上层应用来完成。
Message
Raft集群中节点之间的通讯都是通过传递不同的Message来完成的,这个Message结构就是一个非常general的大容器,它涵盖了各种消息所需的字段。
|
|
- Type:当前传递的消息类型,它的取值有很多个,但大致可以分成两类:
- Raft 协议相关的,包括心跳MsgHeartbeat、日志MsgApp、投票消息MsgVote等。
- 上层应用触发的(没错,上层应用并不是通过api与raft库交互的,而是通过发消息),比如应用对数据更改的消息MsgProp(osal)。
不同类型的消息会用到下面不同的字段:
- To, From分别代表了这个消息的接受者和发送者。
- Term:这个消息发出时整个集群所处的任期。
- LogTerm:消息发出者所保存的日志中最后一条的任期号,一般
MsgVote会用到这个字段。 - Index:日志索引号。如果当前消息是
MsgVote的话,代表这个candidate最后一条日志的索引号,它跟上面的LogTerm一起代表这个candidate所拥有的最新日志信息,这样别人就可以比较自己的日志是不是比candidata的日志要新,从而决定是否投票。 - Entries:需要存储的日志。
- Commit:已经提交的日志的索引值,用来向别人同步日志的提交信息。
- Snapshot:一般跟
MsgSnap合用,用来放置具体的Snapshot值。 - Reject,RejectHint:代表对方节点拒绝了当前节点的请求(MsgVote/MsgApp/MsgSnap…)
log_unstable.go
顾名思义,unstable数据结构用于还没有被用户层持久化的数据,它维护了两部分内容snapshot和entries:
|
|
entries代表的是要进行操作的日志,但日志不可能无限增长,在特定的情况下,某些过期的日志会被清空。那这就引入一个新问题了,如果此后一个新的follower加入,而leader只有一部分操作日志,那这个新follower不是没法跟别人同步了吗?所以这个时候snapshot就登场了 - 我无法给你之前的日志,但我给你所有之前日志应用后的结果,之后的日志你再以这个snapshot为基础进行应用,那我们的状态就可以同步了。因此它们的结构关系可以用下图表示2:
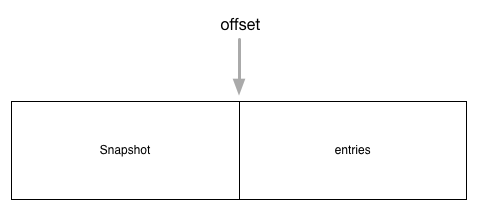
这里的前半部分是快照数据,而后半部分是日志条目组成的数组entries,另外unstable.offset成员保存的是entries数组中的第一条数据在raft日志中的索引,即第i条entries在raft日志中的索引为i + unstable.offset。
storage.go
这个文件定义了一个Storage接口,因为etcd中的raft实现并不负责数据的持久化,所以它希望上面的应用层能实现这个接口,以便提供给它查询log的能力。
另外,这个文件也提供了Storage接口的一个内存版本的实现MemoryStorage,这个实现同样也维护了snapshot和entries这两部分,他们的排列跟unstable中的类似,也是snapshot在前,entries在后。从代码中看来etcdserver和raftexample都是直接用的这个实现来提供log的查询功能的。
log.go
有了以上的介绍unstable、Storage的准备之后,下面可以来介绍raftLog的实现,这个结构体承担了raft日志相关的操作。
raftLog由以下成员组成:
- storage Storage:前面提到的存放已经持久化数据的Storage接口。
- unstable unstable:前面分析过的unstable结构体,用于保存应用层还没有持久化的数据。
- committed uint64:保存当前提交的日志数据索引。
- applied uint64:保存当前传入状态机的数据最高索引。
需要说明的是,一条日志数据,首先需要被提交(committed)成功,然后才能被应用(applied)到状态机中。因此,以下不等式一直成立:applied <= committed。
raftLog结构体中,几部分数据的排列如下图所示2:
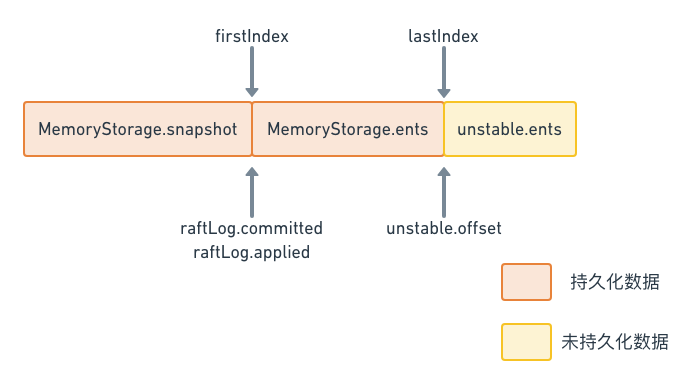
这个数据排布的情况,可以从raftLog的初始化函数中看出来:
|
|
因此,从这里的代码可以看出,raftLog的两部分,持久化存储和非持久化存储,它们之间的分界线就是lastIndex,在此之前都是Storage管理的已经持久化的数据,而在此之后都是unstable管理的还没有持久化的数据。
以上分析中还有一个疑问,为什么并没有初始化unstable.snapshot成员,也就是unstable结构体的快照数据?原因在于,上面这个是初始化函数,也就是节点刚启动的时候调用来初始化存储状态的函数,而unstable.snapshot数据,是在启动之后同步数据的过程中,如果需要同步快照数据时才会去进行赋值修改的数据,因此在这里并没有对它进行操作的地方。
progress.go
Leader通过Progress这个数据结构来追踪一个follower的状态,并根据Progress里的信息来决定每次同步的日志项。这里介绍三个比较重要的属性:
|
|
-
用来保存当前follower节点的日志状态的属性:
- Match:保存目前为止,已复制给该follower的日志的最高索引值。如果leader对该follower上的日志情况一无所知的话,这个值被设为0。
- Next:保存下一次leader发送append消息给该follower的日志索引,即下一次复制日志时,leader会从
Next开始发送日志。
在正常情况下,
Next = Match + 1,也就是下一个要同步的日志应当是对方已有日志的下一条。 -
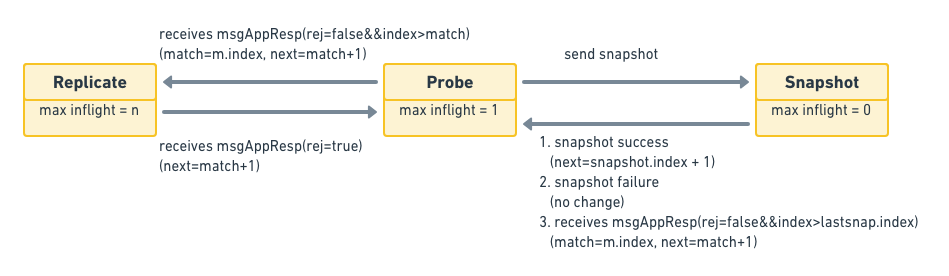
State属性用来保存该节点当前的同步状态,它会有一下几种取值3:- ProgressStateProbe
探测状态,当follower拒绝了最近的append消息时,那么就会进入探测状态,此时leader会试图继续往前追溯该follower的日志从哪里开始丢失的。在probe状态时,leader每次最多append一条日志,如果收到的回应中带有
RejectHint信息,则回退Next索引,以便下次重试。在初始时,leader会把所有follower的状态设为probe,因为它并不知道各个follower的同步状态,所以需要慢慢试探。- ProgressStateReplicate
当leader确认某个follower的同步状态后,它就会把这个follower的state切换到这个状态,并且用
pipeline的方式快速复制日志。leader在发送复制消息之后,就修改该节点的Next索引为发送消息的最大索引+1。- ProgressStateSnapshot
接收快照状态。当leader向某个follower发送append消息,试图让该follower状态跟上leader时,发现此时leader上保存的索引数据已经对不上了,比如leader在index为10之前的数据都已经写入快照中了,但是该follower需要的是10之前的数据,此时就会切换到该状态下,发送快照给该follower。当快照数据同步追上之后,并不是直接切换到Replicate状态,而是首先切换到Probe状态。
-
ins属性用来做流量控制,因为如果同步请求非常多,再碰上网络分区时,leader可能会累积很多待发送消息,一旦网络恢复,可能会有非常大流量发送给follower,所以这里要做flow control。它的实现有点类似TCP的滑动窗口,这里不再赘述。
综上,Progress其实也是个状态机,下面是它的状态转移图:
raft.go
前面铺设了一大堆概念,现在终于轮到实现逻辑了。从名字也可以看出,raft协议的具体实现就在这个文件里。这其中,大部分的逻辑是由Step函数驱动的。
|
|
Step的主要作用是处理不同的消息,所以以后当我们想知道raft对某种消息的处理逻辑时,到这里找就对了。在函数的最后,有个default语句,即所有上面不能处理的消息都落入这里,由一个小写的step函数处理,这个设计的原因是什么呢?
其实是因为这里的raft也被实现为一个状态机,它的step属性是一个函数指针,根据当前节点的不同角色,指向不同的消息处理函数:stepLeader/stepFollower/stepCandidate。与它类似的还有一个tick函数指针,根据角色的不同,也会在tickHeartbeat和tickElection之间来回切换,分别用来触发定时心跳和选举检测。这里的函数指针感觉像实现了OOP里的多态。
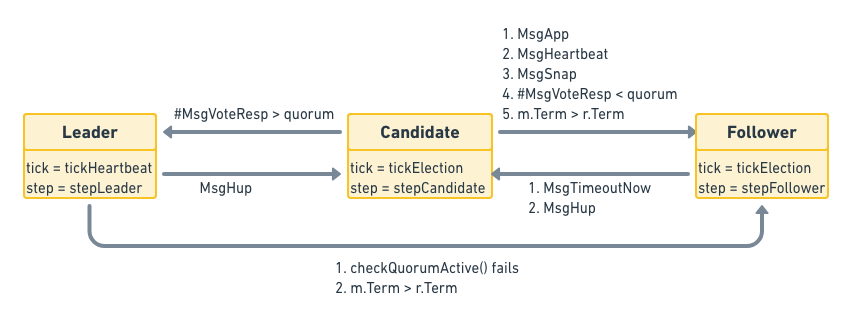
node.go
node的主要作用是应用层(etcdserver)和共识模块(raft)的衔接。将应用层的消息传递给底层共识模块,并将底层共识模块共识后的结果反馈给应用层。所以它的初始化函数创建了很多用来通信的channel,然后就在另一个goroutine里面开始了事件循环,不停的在各种channel中倒腾数据(貌似这种由for-select-channel组成的事件循环在Go里面很受欢迎)。
|
|
propc和recvc中拿到的是从上层应用传进来的消息,这个消息会被交给raft层的Step函数处理,具体处理逻辑我上面有过介绍。
下面来解释下readyc的作用。在etcd的这个实现中,node并不负责数据的持久化、网络消息的通信、以及将已经提交的log应用到状态机中,所以node使用readyc这个channel对外通知有数据要处理了,并将这些需要外部处理的数据打包到一个Ready结构体中:
|
|
应用程序得到这个Ready之后,需要:
- 将HardState, Entries, Snapshot持久化到storage。
- 将Messages广播给其他节点。
- 将CommittedEntries(已经commit还没有apply)应用到状态机。
- 如果发现CommittedEntries中有成员变更类型的entry,调用
node.ApplyConfChange()方法让node知道。 - 最后再调用
node.Advance()告诉raft,这批状态更新处理完了,状态已经演进了,可以给我下一批Ready让我处理。
Life of a Request
前面我们把整个包的结构过了一遍,下面来结合具体的代码看看raft对一个请求的处理过程是怎样的。我一直觉得,如果能从代码的层面追踪到一个请求的处理过程,那无论是从宏观还是微观的角度,对理解整个系统都是非常有帮助的。
Life of a Vote Request
-
首先,在
node的大循环里,有一个会定时输出的tick channel,它来触发raft.tick()函数,根据上面的介绍可知,如果当前节点是follower,那它的tick函数会指向tickElection。tickElection的处理逻辑是给自己发送一个MsgHup的内部消息,Step函数看到这个消息后会调用campaign函数,进入竞选状态。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17// tickElection is run by followers and candidates after r.electionTimeout. func (r *raft) tickElection() { r.electionElapsed++ if r.promotable() && r.pastElectionTimeout() { r.electionElapsed = 0 r.Step(pb.Message{From: r.id, Type: pb.MsgHup}) } } func (r *raft) Step(m pb.Message) error { //... switch m.Type { case pb.MsgHup: r.campaign(campaignElection) } } -
campaign则会调用becomeCandidate把自己切换到candidate模式,并递增Term值。然后再将自己的Term及日志信息发送给其他的节点,请求投票。1 2 3 4 5 6 7 8 9func (r *raft) campaign(t CampaignType) { //... r.becomeCandidate() // Get peer id from progress for id := range r.prs { //... r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx}) } } -
另一方面,其他节点在接受到这个请求后,会首先比较接收到的
Term是不是比自己的大,以及接受到的日志信息是不是比自己的要新,从而决定是否投票。这个逻辑我们还是可以从Step函数中找到:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18func (r *raft) Step(m pb.Message) error { //... switch m.Type { case pb.MsgVote, pb.MsgPreVote: // We can vote if this is a repeat of a vote we've already cast... canVote := r.Vote == m.From || // ...we haven't voted and we don't think there's a leader yet in this term... (r.Vote == None && r.lead == None) || // ...or this is a PreVote for a future term... (m.Type == pb.MsgPreVote && m.Term > r.Term) // ...and we believe the candidate is up to date. if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) { r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)}) } else { r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true}) } } } -
最后当candidate节点收到投票回复后,就会计算收到的选票数目是否大于所有节点数的一半,如果大于则自己成为leader,并昭告天下,否则将自己置为follower:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17func (r *raft) Step(m pb.Message) error { //... switch m.Type { case myVoteRespType: gr := r.poll(m.From, m.Type, !m.Reject) switch r.quorum() { case gr: if r.state == StatePreCandidate { r.campaign(campaignElection) } else { r.becomeLeader() r.bcastAppend() } case len(r.votes) - gr: r.becomeFollower(r.Term, None) } }
Life of a Write Request
-
一个写请求一般会通过调用
node.Propose开始,Propose方法将这个写请求封装到一个MsgProp消息里面,发送给自己处理。 -
消息处理函数
Step无法直接处理这个消息,它会调用那个小写的step函数,来根据当前的状态进行处理。- 如果当前是follower,那它会把这个消息转发给leader。
1 2 3 4 5 6 7 8func stepFollower(r *raft, m pb.Message) error { switch m.Type { case pb.MsgProp: //... m.To = r.lead r.send(m) } } -
Leader收到这个消息后(不管是follower转发过来的还是自己内部产生的)会有两步操作:
- 将这个消息添加到自己的log里
- 向其他follower广播这个消息
1 2 3 4 5 6 7 8 9 10 11func stepLeader(r *raft, m pb.Message) error { switch m.Type { case pb.MsgProp: //... if !r.appendEntry(m.Entries...) { return ErrProposalDropped } r.bcastAppend() return nil } } -
在follower接受完这个log后,会返回一个
MsgAppResp消息。 -
当leader确认已经有足够多的follower接受了这个log后,它首先会commit这个log,然后再广播一次,告诉别人它的commit状态。这里的实现就有点像两阶段提交了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25func stepLeader(r *raft, m pb.Message) error { switch m.Type { case pb.MsgAppResp: //... if r.maybeCommit() { r.bcastAppend() } } } // maybeCommit attempts to advance the commit index. Returns true if // the commit index changed (in which case the caller should call // r.bcastAppend). func (r *raft) maybeCommit() bool { //... mis := r.matchBuf[:len(r.prs)] idx := 0 for _, p := range r.prs { mis[idx] = p.Match idx++ } sort.Sort(mis) mci := mis[len(mis)-r.quorum()] return r.raftLog.maybeCommit(mci, r.Term) }
Conclusion
Etcd里的raft模块只实现了raft共识算法,而像消息的网络传输,数据存储都由上层应用来完成。这篇文章先介绍了基本的数据结构,然后在这些数据结构的基础上引入了raft算法。同时,这里还以一个投票请求和写请求为例,介绍了一个请求从接受到应答的完整处理过程。
但到目前为止,我们还有很多细节没有涉及,比如说Linearizable Read,snapshot机制,WAL的存储与回放,所以希望你能以这篇文章为基础,顺藤摸瓜,继续深入研究下去。