1. 简介
BoltDB 起源于 LMDB(Lightning Memory-Mapped Database),基本可以视作 LMDB 的 Golang 简易实现版(?)。
LMDB 目前仍广泛应用在机器学习领域,从名字也可以看出来它的主要卖点在于使用了内存映射(mmap)技术,这使得它的读性能有时甚至能赶上纯内存的数据库。BoltDB 同样也继承了这个优点,所以读请求居多的 etcd 才选择它作为底层存储(?)。
BoltDB 使用B+ tree来索引数据,这在LSM tree政治正确的今天,它倒显得有些复古。LSM 的特点在于写入简单,读取复杂。而B+ tree正好相反,因此这里我们就以 BoltBD 的写入流程为例,重温一下这个古老的技艺。
2. 数据结构
BoltDB 使用的数据模型比较简单,比较重要的有page、node、freelist、meta、tx。下面,按照自底向上的出场顺序,简单介绍下各个角色,更详细的解说请自行参阅代码。
2.1. 磁盘布局
2.1.1. Page
BoltDB 读写数据的基本单元是一个page,默认大小为 4KiB,与操作系统的page size对齐,这意味着即使用户只需读写1 Byte的内容,但实际发生的 IO 大小却是 4KiB 的整数倍。磁盘中的文件可以理解为一个一个的page顺序排列而成,每个page的布局如下:

Page Header共占 16 Byte,字段含义:
id- page 在磁盘文件中的顺序编号,主要用于寻址。flags用于表示该 page 所代表的类型,比如:branch,leaf,meta或freelist。count- 该 page 中目前所容纳的元素个数,不同的类型有不同的解释,比如在叶子节点可以理解为 KV 键值对个数。overflow- 如果该 page 所承载的逻辑对象超过 4KiB,那overflow就代表接下来的若干个 page 表示的是同一逻辑对象。
剩余一个通用的ptr字段用于指向实际内容,不同数据类型有着不同的解释方式。
2.1.2. 读流程
由于数据文件已经通过mmap映射到了db.data字段,所以读操作非常简单,我们把它当做一个无限长的一维数组,将page id作为数组下标寻址,再来一次类型强转的操作就行了,整个过程完全实现了zero-copy:
|
|
2.1.3. 写流程
写操作并不是通过mmap完成,而是使用的pwrite——在特定的 offset 写入内存中强转为byte的数组:
|
|
所以 BoltDB 对磁盘文件的读写非常简单粗暴,就是一个byte和page之间的强制类型转换——没有考虑考虑大小端,也没有序列化和反序列化的开销,甚至没有 crc 校验,直接一个 dump 了一个原始的内存结构。
2.2. 内存布局
2.2.1. Node
磁盘中的page,读取到内存中就是node对象,这个实例化的过程,代码中用materialized来描述。根据page.overflow的取值,一个node可能横跨多个page。node的逻辑含义代表一个B+ tree的节点,其中两个比较重要的字段:
isLeaf- 用来表示该node存放的是一个中间的分支节点(branch),还是叶子节点(leaf)。inodes- 一个有序数组,代表该page中存放的 KV 对,通过二分查找可以快速定位指定的key。
2.2.2. Branch Page
分支节点被划分成两段——指向key位置的offset和具体的key,可以理解为一种定长header(offset)+不定长body(key)的编码方式,但offset和key分开存放。这使得查找的时候,可以在定长的offset段通过二分快速定位到中间的某个key的指针,再读取ksize大小的内容,从而获得原始的key。
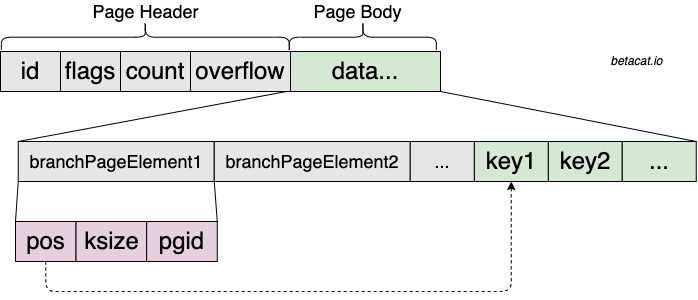
整体布局是不是有点类似类似关系数据库中的Slotted Pages?
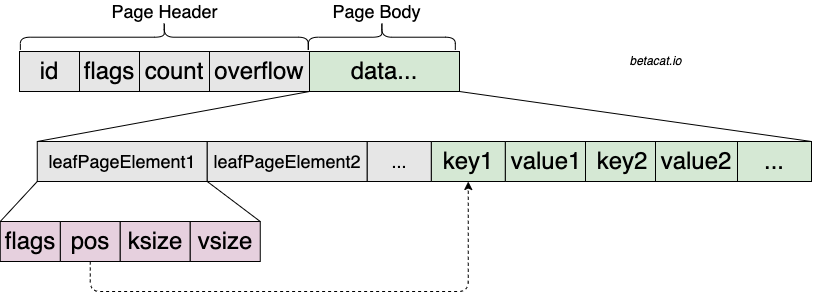
2.2.3. Leaf Page
叶子节点跟分支节点很类似,只不过其中的pgid字段被替换成了vsize,代表存储的value长度,而value的值则被放置到了key后面:
除了上述的B+ tree节点外,还有两个元数据节点也比较重要:
2.2.4. Freelist
BoltDB 的B+ tree借鉴了 append-only 的写入方式,这样能让写请求和读请求隔离开,互不影响,但一直 append 的话磁盘容易写爆,LSM 的做法就是后台分层 dump,而 BoltDB 的做法则是维护一个freelist,用来记录已经被释放的page,下次分配时,优先从freelist中复用,实在没有再去re-mmap扩容。
因此 BoltDB 的文件只会增大,而不会因为数据的删除而减少。
freelist的再分配也实现的非常简单粗暴——从前往后查找,直到找到符合要求的n个连续的页:
|
|
2.2.5. Meta
meta页共两个(为什么使用两个我们下面会揭晓),固定在数据库文件的前两个 page 上。它提供了一些数据库全局的视角,比如:
root- 当前生效的B+ tree的根节点,写事务提交时,这个字段成功更新才意味事务成功提交了。freelist- freelist 列表存在哪一页。pgid- 当前已分配的page最高值,用来做高水位检测。txid- 事务版本号,由写事务递增,读事务读取txid更高且有效的meta页。它的主要作用是用来控制只读事务的可见性,以及释放已经关闭的读事务所占据的脏页。
官方文档提到,长时间不关闭的读事务会导致脏页无法被回收,因为一个读事务相当于 pin 住了它所有涉及的页,后续的写事务不能冒然回收并覆改。
3. 事务
BoltDB 实现了一个 MVCC 语义的事务,读事务读不到在它之后开启的写事务的更改,哪怕这个写事务已经提交。因为每个事务开始的时候都会将meta信息 copy 一份在自己的内存里,相当于做了一个快照,这样之后不管磁盘上的meta页如果变化,都不会影响到自己内存的拷贝。而且写事务回刷脏页都会重新分配一个空闲页,而不是原地覆盖,这就使得读写事务无论在磁盘还是内存中,都没有交集,从而实现了无锁环境下的并发读写。
整个 MVCC 的基础在于它的 COW(copy-on-write) 机制,写事务首先把要变更的页面读上来,在内存里完成业务的Put/Delete操作,然后在提交的时候做一次 B 树的分裂和合并,使得整个变更路径上的节点都能维持平衡。最后再写到新的页面上去。
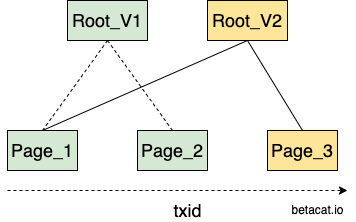
BoltDB 通过简单的 COW 机制实现了事务,避免了使用复杂的 redo/undo log。
4. 组合一下
介绍完上述概念后,我们终于可以理解 BoltDB 是怎样写数据的了:
- 用户开启一个读写事务,BoltDB 内部完成一些初始化动作,包括拷贝一份
meta页到内存中。 - 用户调用更新接口
Put,BoltDB 内部通过迭代器Cursor定位到具体的page和page上的element。 - 将
page反序列化成内存中的node,插入或更改对应的KV。 - 用户调用
Commit接口,BoltDB 通过合并和分裂操作,保持B+ tree的平衡性,并将所有操作过的page及其父节点标记为dirty。 - 通过
freelist搜索能容纳所有脏页的连续空闲列表,如果找不到,则扩大数据库文件,并重新mmap。 - 脏页被回写到磁盘上,并通过
fdatasync确保数据持久化成功。 - 指向最新根节点的
meta页通过覆盖写的方式,写到文件头部,并通过fdatasync确保元数据持久化成功。
4.1. 数据一致性保证
上述各个步骤都可能失败,我们来看看在各种异常场景下,BoltDB 是如何保证数据一致性的:
- 用户调用
Commit前失败,数据未落盘,没有一致性问题。 - 用户调用
Commit后,分配空闲页或者写脏页失败,Commit调用返回出错,用户感知。 - 写脏页成功(包括
fdatasync),表明数据页成功落盘,但更新meta页失败,Commit调用返回出错,用户感知。- 这其中,如果
meta页并没有原子性的写完,那下一个事务在查找meta的时候,meta.validate()方法就会校验失败,从而防止该事务读到一个损坏的记录,这就是为什么要使用两个meta页的原因。 meta更新失败并不影响原来的那棵 B 树,且新写入的page会在下一个事务中变成free page被覆盖。
- 这其中,如果
- 更新
meta页成功(包括fdatasync),表明数据和元数据都已经持久化成功,Commit可以给用户一个安全的承诺了。